
Disaster Recovery: облака и аварийное восстановление IT-инфраструктуры
Чем быстрее информационные системы возобновят работу, тем меньше последствий. Поэтому компании создают катастрофоустойчивые инфраструктуры, развертывая резервные мощности на физических серверах или в облаках.
По прогнозам компании Grand View Research, к 2025 году объем мирового рынка решений для аварийного восстановления достигнет 26,23 млрд долларов США. Спрос растет из-за того, что IT-системы становятся сложнее, поэтому увеличивается число случаев отказа инфраструктуры вследствие внешних и внутренних угроз.
Самый быстрый рост ожидается в сегменте малого и среднего бизнеса — такие компании будут активно внедрять облачные решения Disaster Recovery, которые стали доступнее. Мы расскажем, как работают сервисы восстановления IT-инфраструктуры в облаках и как сделать работу бизнеса непрерывной.
Что такое Disaster Recovery
Disaster Recovery (DR) или катастрофоустойчивость — способность IT-инфраструктуры восстановиться после катастрофы.
Это часть планирования непрерывности бизнеса (Business Continuity, ВС), в которую входят процессы, методы и оборудование для того, чтобы критичные функции бизнеса выполнялись бесперебойно. То есть компания должна продолжать работать, несмотря на стихийные бедствия, атаки, внутренние сбои, или хотя бы быстро восстановить работу и не потерять важные данные.
Для этого основные системы хранения и обработки данных резервируют на удаленной площадке — физическом оборудовании или через облачных провайдеров. Если ЦОД компании распределен по нескольким площадкам, нужно организовать каналы связи между ними, составить план резервного копирования и восстановления систем.
Экономика Disaster Recovery: время восстановления и точка восстановления
Есть два ключевых параметра Disaster Recovery, которые влияют на стоимость катастрофоустойчивой системы, и ущерб для бизнеса в случае сбоя.
- RTO (recovery time objective) — время, за которое система должна восстановить работу. Например, если RTO три часа, значит, инфраструктура заработает не позже, чем через три часа. Если RTO несколько секунд, система заработает почти сразу, пользователь может даже не заметить сбоя. В некоторых решениях DR можно настроить автоматическое переключение трафика на резервную инфраструктуру, она возьмет на себя нагрузку, пока основной ЦОД не восстановят. Допустимая величина RTO зависит от потребностей бизнеса. Например, для крупных онлайн-ритейлеров простой в течение 2-3 часов — потеря множества клиентов и огромных денег. А для веб-сайтов с небольшим трафиком такой сбой может быть некритичным.
- RPO (recovery point objective) — время, за которое могут быть потеряны данные в результате инцидента. Так, если RPO два часа, после восстановления системы потеряются данные не более чем за два часа до сбоя. Например, может быть утрачена информация за 10 минут или 1.5 часа, но не за 2.5 часа. Если RPO равно несколько секунд, практически все данные системы сохранятся. Для некоторых бизнесов низкое RPO критично, например для банков, где нельзя терять данные о транзакциях даже за минуту. Этот показатель определяет, как часто бизнесу нужно делать копии IT-инфраструктуры. Иногда достаточно копировать данные раз в несколько часов, иногда надо создавать резервные копии системы синхронно, в реальном времени, чтобы в двух инфраструктурах хранилась одинаковая информация и ничего не потерялось.
Чем меньше RTO и RPO, тем дороже решение: систему, которая моментально восстанавливается после сбоя и не теряет данные, организовать сложнее.

Зависимость стоимости от величины RTO/RPO
Чтобы выбрать подходящую модель аварийного восстановления, нужно посчитать, какие убытки понесет бизнес в результате простоя. Потом подобрать такие RTO и RPO, когда вероятные потери перевешивают затраты на организацию Disaster Recovery. То есть найти баланс между расходами на катастрофоустойчивость и убытками компании в случае катастрофы с учетом времени восстановления бизнес-процессов и объема потери данных.

Выбор оптимального решения
Что лучше для Disaster Recovery: резервный ЦОД или облако
При классическом подходе к аварийному восстановлению инфраструктуру дублируют в резервный дата-центр: организуют второй ЦОД, который либо полностью дублирует рабочий, либо берет на себя создание и хранение копий данных, критичных для бизнеса.
Вместо того, чтобы создавать собственную резервную площадку, компания может перейти на Cloud DRaaS — облачные сервисы для быстрого аварийного восстановления IT-инфраструктуры. Disaster Recovery в этом случае предоставляется облачным провайдером как услуга.
Это дешевле и проще, чем строить вторую IT-инфраструктуру. Сравним Cloud DRaaS с классическим вариантом — собственным резервным ЦОД,
Организация
Резервный ЦОД. Его сложно организовать. Дублирующая инфраструктура большую часть времени простаивает, однако, нужно закупить или арендовать оборудование, настроить, обслуживать, ремонтировать и обновлять его. Нужен обслуживающий персонал, важно настроить репликации, переключение доменов и DNS-записей, чтобы система заработала в случае аварии. Не всегда можно совместить с нужными платформами.
Cloud DRaaS. Внедрить просто. Можно настроить облачную инфраструктуру силами собственных специалистов или заказать консалтинг у провайдера. Не нужно обслуживать резервную систему и нанимать персонал. Облачные решения интегрируются с большинством популярных платформ, они могут работать с разным оборудованием и приложениями.
Стоимость
Резервный ЦОД. Высокая стоимость. Нужны серьезные вложения для создания и обслуживания дублирующей инфраструктуры, электропитания ЦОД, ремонта и замены оборудования, оплаты услуг персонала, покупки лицензий для серверов и хранилищ, обеспечения безопасности.
Cloud DRaaS. Стоимость зависит от модели, которую использует компания, есть разные решения, отличающиеся по цене. Однако облачные технологии всегда дешевле собственного резервного ЦОД, так как не надо платить за машинные залы, их обслуживание и работу инженеров. При размещении инфраструктуры в облаке часто используют модель Pay-As-You-Go, когда оплата идет за фактически использованные ресурсы — если система не используется, бизнес платит меньше.
Три модели облачных решений Disaster Recovery
В зависимости от масштаба бизнеса и желаемого RTO/RPO можно выбрать три варианта аварийного восстановления в облаке.
Решение для резервного копирования и восстановления (Backup & Restore Solution). Информация копируется и восстанавливается по заданному расписанию, например, раз в сутки или несколько часов. Скопированная IT-инфраструктура помещается в надежное облачное хранилище, например, облачное решение для «горячего хранения» данных Hotbox. Когда наступает катастрофа, клиент восстанавливает информационные системы из облака. Если катастрофа происходит между копированиями, то данные, которые не были сохранены, потеряются.
RTO и RPO у этого облачного решения самые высокие — от 2-3 часов, зато оно экономично и подходит малому бизнесу, которому не критична непрерывная работа инфраструктуры.
Решение можно сравнить с поломкой автомобиля во время поездки. Например, лопнула шина или порвался ремень генератора, а у водителя нет запасных. Теперь нужно ждать эвакуатор, тратить время на ремонт в автосервисе или шиномонтаж. Чем больше повреждения, тем дольше автомобиль никуда не поедет.
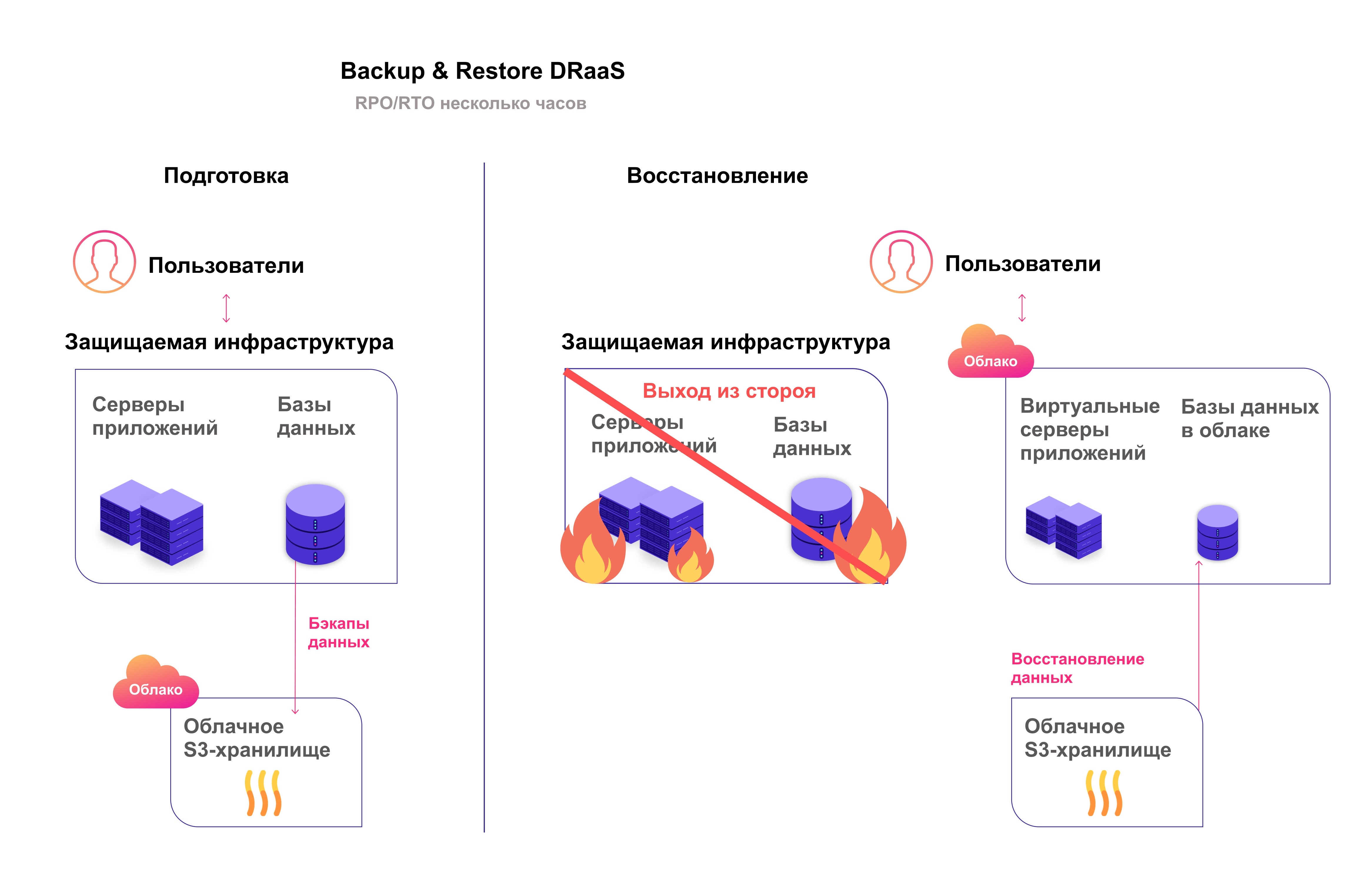
Копии инфраструктуры делают периодически и хранят в облачном хранилище
Такой вариант резервного копирования и восстановления можно реализовать и без облака: обычно данные копируют на ленту и хранят в том же ЦОДе, что не станет страховкой от пожара. Кроме этого, в таких случаях восстановление системы может занять несколько дней. Облачные хранилища вроде Hotbox ускоряют процесс, так как позволяют оперативно вытащить данные. Поэтому можно вернуть систему к работе за несколько часов.
Решение для быстрого восстановления (Quick Recovery Solution). Информационная система содержится в облаке в минимально рабочей конфигурации. Рабочая и резервная базы данных непрерывно синхронизируются в инкрементальном режиме — то есть сначала делают полную копию системы, а потом копируют только новую информацию. В облаке содержатся готовые к запуску шаблоны виртуальных машин и приложений. После сбоя IT-инфраструктуру можно запустить одной кнопкой.
После аварии время нужно только на запуск приложений, в облаке хранится актуальная копия информационной системы, поэтому данные не теряются. Этот вариант дороже первого, так как он подразумевает платное агентское решение, клиент платит за использование ресурсов и образов, организацию непрерывного копирования и систему восстановления «по одной кнопке». Зато RTO/RPO решения меньше: до получаса/несколько минут. Оно универсально и подходит большинству компаний, в том числе интернет-магазинам, где важно не терять данные о заказах и транзакциях. Кроме того, хранение инфраструктуры в «спящем режиме» дешевле, чем организовать и обслуживать вторую боевую инфраструктуру, находящуюся в рабочем состоянии.
Если продолжить аналогию со сломанным автомобилем, то оно похоже на ситуацию, когда поломка случилась, но под рукой все, чтобы ее исправить. Не надо вызывать эвакуатор и ехать в сервис, однако, нужно потратить немного времени на ремонт.

В облаке содержится актуальная копия рабочей IT-инфраструктуры
Параллельная инфраструктура (Multi-Site Solution). Клиент запускает в облаке IT-инфраструктуру, аналогичную боевой. Базы данных постоянно синхронизируются, приложения обновляются параллельно в двух инфраструктурах.
Синхронность записи данных зависит от системы, есть два варианта с учетом нужной точки восстановления (RPO):
- синхронный — информация сразу записывается в две системы, данные не теряются даже за секунду;
- асинхронный — информация сначала записывается в одну систему, потом тут же переносится во вторую, потеря времени на запись данных измеряется в секундах.
Переключение трафика на резервную инфраструктуру может быть ручным или автоматическим. В таком варианте простоя после аварии практически не будет, но решение подходит не для всех IT-инфраструктур.
Параллельная активная инфраструктура подходит компаниям, где работа информационных систем критична для бизнеса: не должно быть сбоев, потеря данных недопустима. Например, финансовые компании и банки, госуслуги, крупные IT-компании. В этом решении RTO/RPO минимальны: несколько минут/несколько секунд. Оно самое дорогое из облачных вариантов Disaster Recovery, но его стоимость меньше, чем стоимость резервного дата-центра.
Еще одно преимущество параллельной инфраструктуры: возможность эластичного масштабирования — если нужны дополнительные вычислительные ресурсы или память, они выделяются динамически в широких пределах.
Решение можно сравнить с электроснабжением операционных. Всегда есть резервный источник энергии: если отключат электричество, то аппаратура, поддерживающая жизнь пациента, не выключится, произойдет переключение на автономную электростанцию.
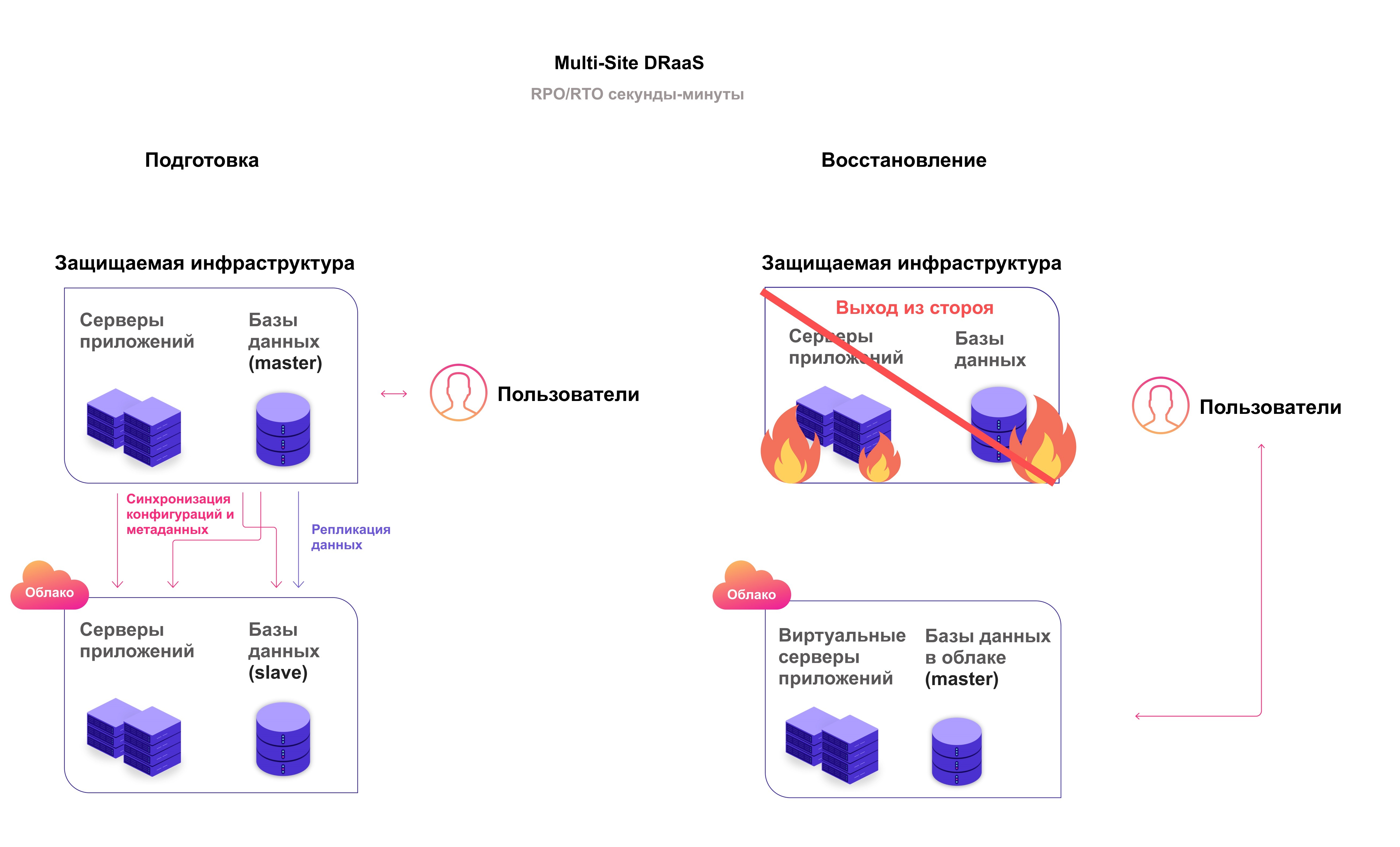
При отключении основной инфраструктуры трафик можно переключить на резервную
Есть похожие решения, в которых облачная инфраструктура не стоит «в резерве», а также ставится под нагрузку и представляет собой «второе плечо» инфраструктуры. При этом выполняется балансировка нагрузки с равномерным распределением запросов между инфраструктурами. Строго говоря, это решение не относится к классу DRS, но позволяет на сходной с DRS архитектуре организовать высокодоступный геораспределенный сервис (high availability).
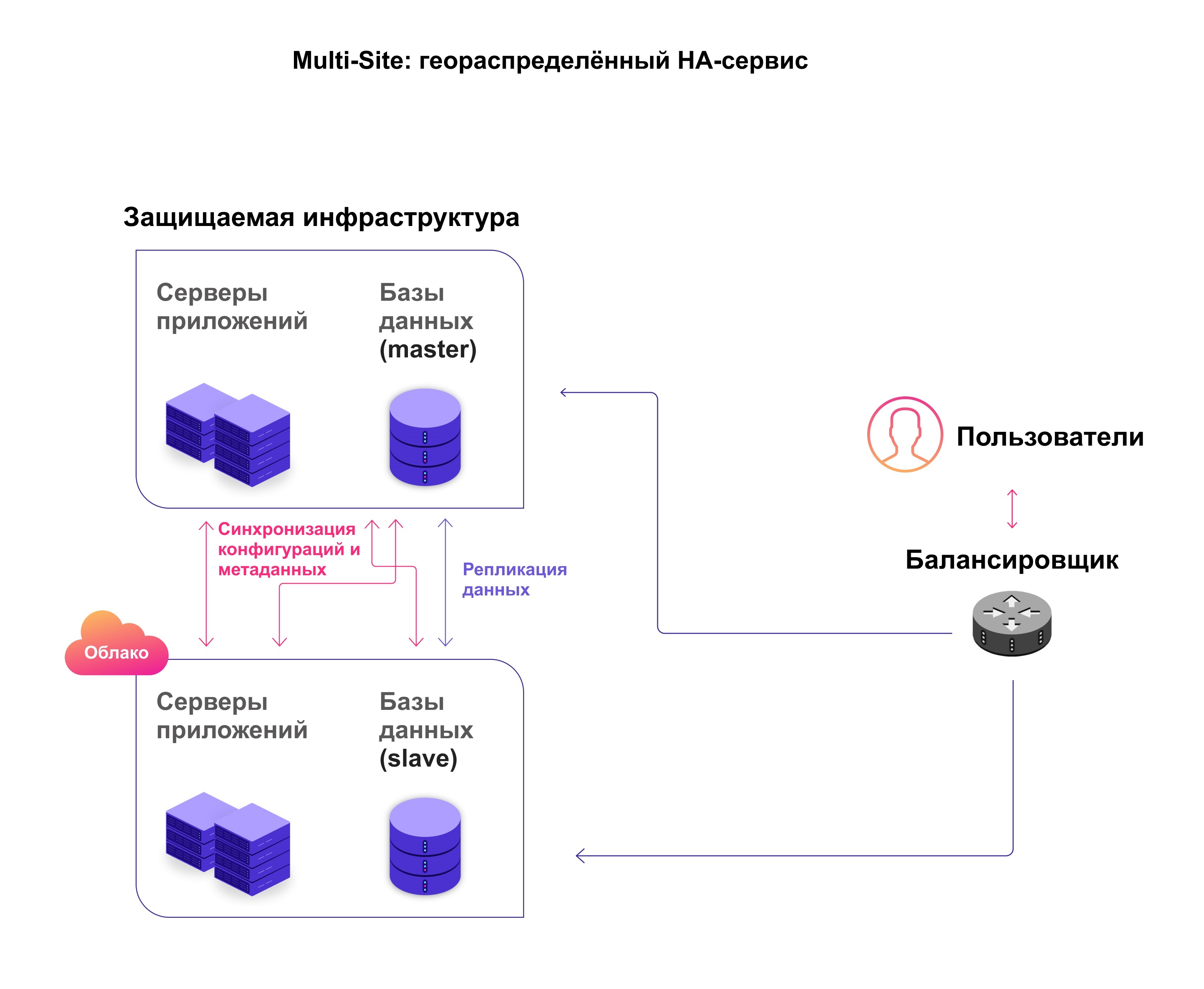
Два плеча инфраструктуры с балансировкой нагрузки
Как защитить IT-инфраструктуру от катастроф
- Использовать решения Disaster Recovery, которые помогут обеспечить непрерывность работы бизнеса и избежать потери данных.
- Найти баланс между расходами на поддержание катастрофоустойчивости и потерями компании в случае сбоя.
- Использовать облачные решения Disaster Recovery, которые проще в организации и дешевле, чем резервный собственный ЦОД.
- Подобрать облачный сервис Cloud DRaaS в соответствии с допустимыми значениями RTO/RPO.





