
Как использовать Prometheus для обнаружения аномалий в GitLab
Одной из базовых функций языка запросов Prometheus является агрегация временных рядов в режиме реального времени. Также язык запросов Prometheus можно использовать для обнаружения аномалий в данных временных рядов.
Перевели статью инженера команды инфраструктуры GitLab, где вы найдете примеры кода, которые сможете попробовать на своих системах.
Для чего нужно определение аномалий
Существует четыре основных причины, определяющих важность обнаружения аномалий для GitLab:
- Диагностика инцидентов: мы можем обнаружить, какие сервисы вышли за свои обычные рамки, уменьшив время выявления инцидента (MTTD), и, соответственно, предложить более быстрое решение проблемы.
- Обнаружение снижения производительности: например, если в сервис внесена регрессия, приводящая к тому, он слишком часто обращается к другому сервису, мы сможем быстро обнаружить и устранить эту проблему.
- Выявление и устранение злоупотреблений: GitLab предоставляет механизмы доставки и интеграции (GitLab CI/CD) и хостинга (GitLab Pages) и ограниченное число пользователей, которые могут этими механизмами пользоваться.
- Безопасность: обнаружение аномалий важно для выявления необычных тенденций во временных рядах GitLab.
По этим и другим причинам автор статьи решил разобраться, как настроить определение аномалий во временных рядах GitLab при помощи запросов и правил Prometheus.
Какой уровень агрегации правильный
Для начала временные ряды должны быть правильно агрегированы. В примере ниже использован стандартный счетчик http_requests_total для получения данных, хотя также подошли бы и многие другие метрики.
http_requests_total{
job="apiserver",
method="GET",
controller="ProjectsController",
status_code="200",
environment="prod"
}
У этой тестовой метрики есть несколько параметров: метод (method), контроллер (controller), код статуса (status_code), окружение (environment), плюс параметры, добавленные самим Prometheus, например, job и instance.
Теперь нужно выбрать правильный уровень агрегации данных. Слишком много, слишком мало — все это важно для детектирования аномалий. Если данные слишком сильно агрегированы, возможны две потенциальные проблемы:
- Вы можете пропустить аномалию, так как агрегация скрывает проблемы, возникающие в подмножествах ваших данных.
- Если вы обнаружили аномалию, то трудно ее связать с отдельной частью вашей системы без дополнительных усилий.
Если данные мало агрегированы, это может привести к увеличению количества ложных срабатываний, а также к неправильной трактовке валидных данных как ошибочных.
Исходя из нашего опыта, самый правильный уровень агрегации — уровень сервиса, то есть мы включаем метку работы (job) и окружения (environment), а все остальные метки отбрасываем.
Агрегация, о которой мы будем говорить на протяжении всей статьи, включает: job — http_request, агрегация — пять минут, которая рассчитывается на основе работы и окружения за пять минут.
- record: job:http_requests:rate5m
expr: sum without(instance, method, controller, status_code)
(rate(http_requests_total[5m]))
# --> job:http_requests:rate5m{job="apiserver", environment="prod"} 21321
# --> job:http_requests:rate5m{job="gitserver", environment="prod"} 2212
# --> job:http_requests:rate5m{job="webserver", environment="prod"} 53091
Из приведенного примера видно, что из ряда http_requests_total выбираются подмножества в разрезе работы и окружения, потом считается их количество за пять минут.
Использование Z-оценки для обнаружения аномалий
Основные принципы статистики могут быть применены для обнаружения аномалий.
Если вы знаете среднее значение и стандартное отклонение ряда Prometheus, то можно использовать любую выборку в ряду для подсчета z-оценки.
То есть z-оценка = 0 означает, что z-оценка идентична среднему значению в наборе данных со стандартным распределением, а z-оценка = 1 означает, что стандартное отклонение = 1.0 от среднего значения.
Мы предполагаем, что базовые данные имеют нормальное распределение, значит, 99.7% выборок имеют z-оценку от 0 до 3. Чем дальше z-показатель от нуля, тем меньше вероятность его существования.
Применим это свойство для выявления аномалий в сериях данных Prometheus:
- Рассчитаем среднее и стандартное отклонение для метрики, используя данные с большим размером выборки. Для этого примера мы используем данные за неделю. Если мы предполагаем, что оценка записей проводится раз в минуту, то за неделю у нас будет чуть более 10 000 семплов.
# Long-term average value for the series
- record: job:http_requests:rate5m:avg_over_time_1w
expr: avg_over_time(job:http_requests:rate5m[1w])
# Long-term standard deviation for the series
- record: job:http_requests:rate5m:stddev_over_time_1w
expr: stddev_over_time(job:http_requests:rate5m[1w])
- Мы можем посчитать z-оценку для запроса Prometheus, как только получим среднее и стандартное отклонение для агрегации.
# Z-Score for aggregation
(
job:http_requests:rate5m -
job:http_requests:rate5m:avg_over_time_1w
) / job:http_requests:rate5m:stddev_over_time_1w
Базируясь на статистических принципах нормальных распределений, предположим, что любое значение, выходящее за пределы диапазона от +3 до -3, будет аномалией. Соответственно, мы можем создать предупреждение о таких аномалиях. Например, будем получать оповещение, когда наша агрегация выходит за пределы этого диапазона более чем на пять минут.
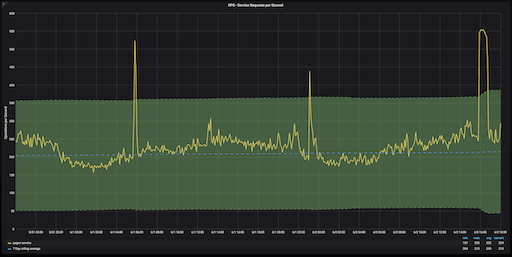
Z-оценки бывает тяжело интерпретировать на графиках, так как эта величина не имеет единицы измерения. Но аномалии на этом графике определить очень просто. Всё, что выходит за пределы зеленой зоны, которая показывает коридор величин с z-оценкой от -3 до +3, будет аномальным значением.
Что делать, если распределение данных не является нормальным
Мы делаем допущение, что распределение данных является нормальным. В противном случае вычисленная нами z-оценка будет неверной.
Существует масса статистических приемов для определения нормальности распределения данных, но лучшим способом будет проверить, что у ваших данных z-оценка лежит в диапазоне от -4.0 до +4.0.
(
max_over_time(job:http_requests:rate5m[1w]) -
avg_over_time(job:http_requests:rate5m[1w])
) / stddev_over_time(job:http_requests:rate5m[1w])
# --> {job="apiserver", environment="prod"} 4.01
# --> {job="gitserver", environment="prod"} 3.96
# --> {job="webserver", environment="prod"} 2.96
(
min_over_time(job:http_requests:rate5m[1w]) -
avg_over_time(job:http_requests:rate5m[1w])
) / stddev_over_time(job:http_requests:rate5m[1w])
# --> {job="apiserver", environment="prod"} -3.8
# --> {job="gitserver", environment="prod"} -4.1
# --> {job="webserver", environment="prod"} -3.2
Два запроса Prometheus, демонстрирующие минимальные и максимальные z-оценки
Если ваши результаты лежат в диапазоне от -20 до +20, это значит, что использовано слишком много данных, и результаты искажены. Помните также, что вы должны работать с агрегированными рядами. Метрики, которые не имеют нормального распределения, включают в себя такие параметры, как частота ошибок, задержки, длины очередей и так далее. Но многие из этих метрик будут работать лучше с фиксированными порогами для оповещения.
Обнаружение аномалий с использованием статистической сезонности
Хотя расчет z-оценок хорошо работает с нормальным распределением данных временных рядов, существует второй метод, который может дать еще более точные результаты обнаружения аномалий. Это использование статистической сезонности.
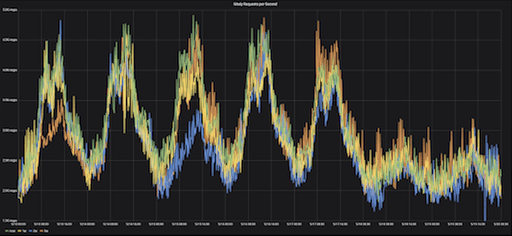
График выше иллюстрирует RPS (количество запросов в секунду) за семь дней — с понедельника по воскресенье, за четыре недели подряд. Этот семидневный диапазон называется «смещением», то есть шаблоном, который будет применяться для измерения.
Каждая неделя на графике разного цвета. На сезонность данных указывает последовательность в тенденциях, указанных на графике — каждое утро понедельника мы наблюдаем схожее повышение RPS, а по вечерам в пятницу мы всегда наблюдаем снижение RPS.
Используя сезонность в наших данных временных рядов, мы можем более точно прогнозировать появление аномалий и их детектирование.
Как использовать сезонность
Для расчета сезонности в Prometheus используют несколько различных статистических механизмов.
Сначала делаем расчет, добавляя тенденцию роста за неделю к результатам предыдущей недели. Тенденция роста рассчитывается так: вычитаем скользящее среднее значение за последнюю неделю из скользящего среднего значения за прошедшую неделю.
- record: job:http_requests:rate5m_prediction
expr: >
job:http_requests:rate5m offset 1w # Value from last period
+ job:http_requests:rate5m:avg_over_time_1w # One-week growth trend
- job:http_requests:rate5m:avg_over_time_1w offset 1w
Первая итерация получается несколько «узкая» — мы используем пятиминутное окно этой недели и предыдущей недели, чтобы получить наши прогнозы.
На второй итерации мы расширяем охват, беря среднее значение за четырехчасовой период за предыдущую неделю и сравнивая его с текущей неделей.
Таким образом, если мы пытаемся предсказать значение метрики в восемь часов утра в понедельник, вместо того же пятиминутного окна за неделю до этого, мы берем среднее значение метрики с шести до десяти часов утра предыдущего понедельника.
- record: job:http_requests:rate5m_prediction
expr: >
avg_over_time(job:http_requests:rate5m[4h] offset 166h) # Rounded value
from last period
+ job:http_requests:rate5m:avg_over_time_1w # Add 1w growth trend
- job:http_requests:rate5m:avg_over_time_1w offset 1w
В запросе указано 166 часов, что на два часа меньше полной недели (7*24=168), так как мы хотим использовать четырехчасовой период, основанный на текущем времени, поэтому нужно, чтобы смещение было на два часа меньше полной недели.

Сравнение фактического RPS с нашим прогнозом показывает, что наши расчеты были довольно точными. Однако у этого метода есть недостаток.
Например, GitLab 1 мая использовали меньше, чем обычно по средам, так как этот день был выходным. Так как расчетная тенденция роста зависит от того, как использовали систему на предыдущей неделе, наши прогнозы на следующую неделю, то есть на среду, 8 мая, дали более низкий RPS, чем на самом деле.
Эту ошибку можно исправить, сделав три прогноза на три недели подряд до среды, 1 мая, то есть на три предшествующие среды. Запрос остается прежним, но смещение корректируется.
- record: job:http_requests:rate5m_prediction
expr: >
quantile(0.5,
label_replace(
avg_over_time(job:http_requests:rate5m[4h] offset 166h)
+ job:http_requests:rate5m:avg_over_time_1w -
job:http_requests:rate5m:avg_over_time_1w offset 1w
, "offset", "1w", "", "")
or
label_replace(
avg_over_time(job:http_requests:rate5m[4h] offset 334h)
+ job:http_requests:rate5m:avg_over_time_1w -
job:http_requests:rate5m:avg_over_time_1w offset 2w
, "offset", "2w", "", "")
or
label_replace(
avg_over_time(job:http_requests:rate5m[4h] offset 502h)
+ job:http_requests:rate5m:avg_over_time_1w -
job:http_requests:rate5m:avg_over_time_1w offset 3w
, "offset", "3w", "", "")
)
without (offset)

Кроме того, нам не нужны три прогноза, нам нужен один прогноз. Среднее значение не вариант, поскольку оно будет размыто нашими искаженными данными RPS от 1 мая. Вместо этого нужно вычислить медиану. У Prometheus нет медианного запроса, но мы можем использовать квантильную агрегацию вместо медианы.
Единственной проблемой является то, что мы пытаемся включить три серии в агрегацию, и эти три серии на самом деле являются одной и той же серией за три недели. Другими словами, у них одинаковые метки, поэтому соединить их сложно.
Чтобы избежать путаницы, мы создаем метку с именем offset и используем функцию label-replace для добавления смещения к каждой из трех недель. Затем в квантильной агрегации отбрасываем эти метки, и это дает нам среднее значение из трех.
- record: job:http_requests:rate5m_prediction
expr: >
quantile(0.5,
label_replace(
avg_over_time(job:http_requests:rate5m[4h] offset 166h)
+ job:http_requests:rate5m:avg_over_time_1w -
job:http_requests:rate5m:avg_over_time_1w offset 1w
, "offset", "1w", "", "")
or
label_replace(
avg_over_time(job:http_requests:rate5m[4h] offset 334h)
+ job:http_requests:rate5m:avg_over_time_1w -
job:http_requests:rate5m:avg_over_time_1w offset 2w
, "offset", "2w", "", "")
or
label_replace(
avg_over_time(job:http_requests:rate5m[4h] offset 502h)
+ job:http_requests:rate5m:avg_over_time_1w -
job:http_requests:rate5m:avg_over_time_1w offset 3w
, "offset", "3w", "", "")
)
without (offset)
Теперь наше прогноз с медианным значением из трех агрегаций стал более точным.
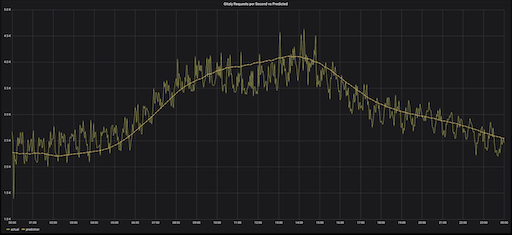
Как узнать, что наш прогноз действительно точен
Чтобы проверить точность прогноза, мы можем вернуться к z-оценке. Ее используют для измерения расхождения выборки с ее прогнозом в стандартных отклонениях. Чем больше стандартное отклонение от прогноза, тем выше вероятность того, что конкретное значение является выбросом.
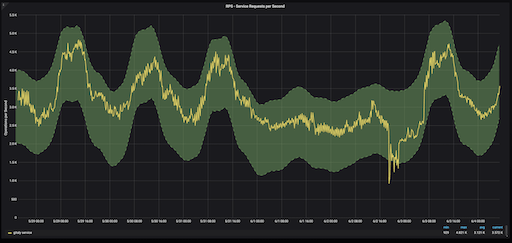
Можно изменить наш график Grafana, чтобы использовать сезонный прогноз, а не еженедельное скользящее среднее значение. Диапазон нормальных значений для определенного времени суток закрашен зеленым цветом. Все, что выходит за пределы зеленой зоны, считается выбросом. В этом случае выброс произошел в воскресенье днем, когда у нашего облачного провайдера возникли некоторые проблемы с сетью.
Хорошей практикой считается использование значения z-оценки в ± 2 для сезонных прогнозов.


Как настроить оповещение при помощи Prometheus
Если хотите настроить оповещение об аномальных событиях, вы можете применить довольно простое правило Prometheus, которое проверяет, находится ли z-оценка показателя в диапазоне между +2 и -2.
- alert: RequestRateOutsideNormalRange
expr: >
abs(
(
job:http_requests:rate5m - job:http_requests:rate5m_prediction
) / job:http_requests:rate5m:stddev_over_time_1w
) > 2
for: 10m
labels:
severity: warning
annotations:
summary: Requests for job {{ $labels.job }} are outside of expected
operating parameters
В GitLab мы используем настраиваемое правило маршрутизации, которое передает оповещение через Slack при обнаружении каких-либо аномалий, но не связывается с нашей службой поддержки.
Как обнаружить аномалии в GitLab с помощью Prometheus
- Prometheus может использоваться для обнаружения некоторых аномалий.
- Правильная агрегация — ключ к поиску аномалий.
- Z-оценка эффективна, если ваши данные имеют нормальное распределение.
- Статистическая сезонность — мощный механизм обнаружения аномалий.




