
Когда данные слишком большие: Data Platform aaS как тренд
Спикер: Дмитрий Лазаренко, директор по продукту VK Cloud (бывш. MCS)
Большие данные (big data) возникают тогда, когда хранить информацию дешевле, чем ее выбросить. Так что люди склонны к накоплению данных. Аналитики Gartner прогнозируют, что в 2020 году мы будем хранить 40 зеттабайт неструктурированной информации. 90% этого объема образовалось за последние 2 года, и объем данных продолжает расти по экспоненте. В 2020 году каждый человек будет генерировать 1,7 МБ данных ежесекундно.
Компании vs большие данные
Данных много, и большая часть компаний, которые есть на рынке, инвестирует в обработку данных и искусственный интеллект, чтобы потом получить выгоду.
Яркий пример – Netflix, который с помощью предиктивной аналитики и обработки большого объема пользовательских данных научился сохранять деньги. Он повышает удержание пользователей, предлагая им нужные сериалы и фильмы. А сэкономить — то же, что и заработать. $1 миллиард Netflix экономит на удержании клиентов каждый год.
97,2 % инвестируют в большие данные и искусственный интеллект.
Мы живем в эпоху IT-connected устройств – у нас есть фитнес-браслеты, в Америке есть электромобили Tesla, в том числе оснащенные системами автономного управления. На самом деле, IT-устройства – главные катализаторы рынка big data и основная причина его роста.
При этом с каждым годом стремительно увеличивается количество IT-устройств в пересчете на одного жителя планеты. Таких устройств становится все больше, и сложно предсказать, какие еще девайсы появятся у нас через несколько лет. По прогнозам, количество IoT-устройств в 2025 году превысит население Земли в 9 раз.
Аналитика и BI больше не роскошь, а неотъемлемая часть бизнеса
- Понимание, что происходит в бизнесе.
- Поддержка принятия решений.
- Оптимизация процессов.
- Управление рисками и прогнозирование.
- Идентификация трендов и поиск точек роста.
- Повышение эффективности.
Информации очень много и ее нужно уметь не просто хранить, а обрабатывать и получать полезный результат. Компании в это инвестируют, потому что это помогает оптимизировать процессы и повысить эффективность бизнеса.
Как оптимизировать обработку данных
Давайте все поместим в DWH
Лет 30 тому назад было популярно складывать все данные в data warehouse (DWH) – структурированное хранилище данных – и потом их анализировать. Но:
- Бизнес-требования меняются быстрее, чем мы можем прогнозировать, особенно в 2019 году.
- Сложность обработки неструктурированных данных, для которых DWH – не лучшее решение.
- Хранение в DWH слишком дорого. Когда мы помещаем в хранилище всю информацию, даже если она ненужная, мы все равно платим за ее хранение. Считается, что только 20 % той информации, которую мы храним, имеет хоть какую-то пользу. Судя по трендам, через 5 лет ее доля достигнет 35 %, но останется 65% «паразитных» данных.
Тогда давайте все поместим в Hadoop
Десять лет назад люди учли недостатки DWH и создали Hadoop, перешли к обработке неструктурированных данных с помощью batch-процессинга. Это помогло уменьшить расходы, но с другой – были и минусы:
- Неэффективная обработка структурированных данных.
- Результат мы получаем не сразу и стоит это дорого.
Так что если, скажем, для задач очистки данных в разы дешевле окажется Hadoop, то для построения enterprise data warehouse в разы дешевле будут DWH-решения.
Значит, построим Data Lake?
Data lake (озеро данных) берет лучшее из подходов DWH и Hadoop. Данные предварительно обрабатываются (фильтруются) с помощью Hadoop’ов, потом их помещают в DWH. На первый взгляд, все хорошо. Но есть проблемы:
- Долго. Типичный data lake состоит из большого количества компонентов, которые нужно уметь связать. На интеграцию разрозненных компонентов может потребоваться много времени, на разработку и построение таких кейсов уйдут годы.
- Плохой ROI — все это требует огромных инвестиций.
- Дефицит экспертизы по администрированию. Говорят, разработчики любят разрабатывать, но не любят администрировать. Аналогично со стеками big data: персонал, который обслуживает эти платформы, часто не имеет квалификации в конкретных нишевых стеках.
Data Platforms и фабрики по обработке данных
Решение – это Data Platform / data fabrics «фабрика по обработке данных». Ее компоненты – Kafka, Hadoop Spark, пакетная обработка, хранилище данных, тесно интегрированные друг с другом. Такова концепция Data Platform. Она помогает сократить время на достижение результата и получить готовый кейс (например, для обработки логов или антиспама). В итоге, когда компания внедряет подобные платформы, она получает не просто технологию, какие-то атомарные «кубики», а готовые рецепты.
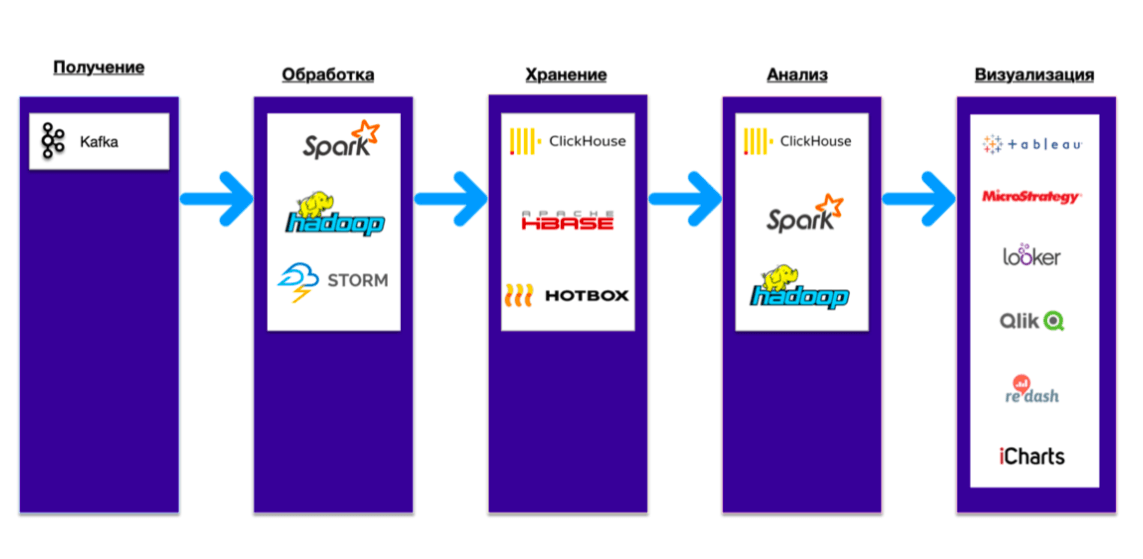
Как взаимодействуют компоненты внутри Data Platform
С Data Platform компании получают готовые рецепты:
- Большие данные. Поиск возможностей на рынке, ad-hoc data, mining, предиктивная аналитика.
- Бизнес-аналитика. Анализ операционной деятельности, поддержка решений, ad-hoc аналитика, data warehousing, ETL/ELT, озера данных.
- Машинное обучение. Нейронные сети, глубокое обучение, распознавание образов, ИИ.
- Безопасность. Выявление спама в письмах и комментариях, fraud detection, защита от злоумышленников.
- Ритейл и e-commerce. Анализ чеков, формирование спецпредложений, управление поставками, внешняя монетизация.
- Телекоммуникации. Customer 360, обработка CDR, предиктивная аналитика неполадок, оптимизация расходов.
- Финансы и банки. Онлайн- и офлайн скоринг, финансовый анализ, fraud detection.
- Сегментация пользователей по действиям на сайте, анализ тональности.
Customer Data Platform
E-commerce и офлайн-коммерция, как и любой другой бизнес, стремятся оптимизировать средний чек и увеличить маржинальность. С помощью решений типа customer Data Platform компания получает данные от веб-сайта через готовые коннекторы, мобильные приложения, иногда через IoT-устройства. Эти клиентские данные помещаются в платформу, а она обогащает их другими данными – например, из соцсетей.
Сейчас в Facebook зарегистрировано около 2 млрд пользователей. Представьте себе, какие результаты вы получите, если обогатите данные своих клиентов данными из этой соцсети. Вы сможете делать клиентам индивидуальные предложения и увеличить продажи. Такие платформы уже существуют, в том числе в России.
IoT Data Platform
Другой тренд – это IoT, главный драйвер больших данных, основная причина их появления и обработки. Есть специализированные big data-платформы, которые заточены под конкретные IoT-стеки: протоколы, трансформацию данных, нотификацию пользователей.
Например, в VK Cloud (бывш. MCS) мы получаем данные от различных IoT-устройств с учетом протоколов типа MQTT, потом преобразуем их и вызываем необходимые системы. Все это связано и поставляется как готовый шаблон для обработки больших данных, оптимизированный для IoT.
Рынок Data Platform
По трендам Gartner рынок уже большой. Среди лидирующих игроков есть, конечно, традиционные вендоры — Oracle, IBM или SAP. Но также есть облачные решения – например, Amazon или Google.
Другая статистика, от Forrester’а, оценивает рынок с точки зрения интеграции фабрики обработки данных. Здесь немного другие игроки, но в то же время есть Hortonworks и Cloudera, которые уже слились.
Среди Data Platform есть такие, которые работают только в облаке. Глобальная тенденция заключается в том, что компании уходят от предоставления платформ для обработки больших данных как софта и отдают их только в облаке, как в Amazon или Google Cloud. Это гиперскейлеры, они могут себе это позволить. Но есть и другие компании – Arm Treasure Data или SnowFlake, которые работают только поверх Amazon или Google Cloud и никак больше.
Почему Data Platform лучше в облаке
Снижение расходов, низкий TCO. Не нужно инвестировать в инфраструктуру, которая редко используется. В случае c data lake вы можете использовать дешевое объектное хранилище, которое предоставляется каждым облачным провайдером и обычно стоит ≈ в три раза дешевле, чем простое хранилище для виртуальных машин.
Но расходы — не самое главное. Более важна автоматизация: платформы для обработки данных в облаке обладают повышенной степенью автоматизации. Благодаря этому вы получаете больше надежности и снижаете затраты на персонал.
Также важна масштабируемость облака: она позволяет решить задачу быстрее за счет масштабирования кластера Hadoop и DWH. То есть вы можете поднять больше shards, когда это необходимо, а потом сжать до меньших размеров. И заплатить минимум, а не огромные деньги. Как результат, растет продуктивность IT.
Пример от 451 Research: финансовый регулятор США перенес платформу для обработки больших данных в облако и смог поднимать полноценные песочницы с предустановленным софтом для больших данных всего за сутки. За счет облака решение задачи сильно ускорилось до 400 раз. Теперь для аналитики и обработки данных, собранных у клиентов за полтора года, требуется не 6–9 месяцев, как раньше, а всего одна неделя.
Плюсы от ухода с on-premise
Еще один показатель эффективности от тесно интегрированных компонентов Data Platform — разработчики и аналитики чаще запускают свои приложения и запросы из облака, по сравнению с on-premise. Они тратят меньше времени времени на рутинные задачи и больше – на что-то более важное, а автоматизация увеличивает качество и снижает себестоимость.
По данным IDС, компании из Fortune 500, которые использовали платформы для обработки больших данных и data lake on-premise, а потом перенесли эти платформы в облако. В результате:
- команды, занятые инжинирингом, стали эффективнее на 33%.
- Управление окружениями стало эффективнее на 46%: с тесно интегрированным “Data Platform PaaS” можно быстро создавать окружения для решения конкретных задач и прототипирования. Это можно сделать примерно за полчаса, а результат получить уже в течение первых суток.
- Downtime снизился на 99%. Конечно, облако может быть надежным. Но в целом простои сокращаются не из-за надежности облачной платформы, а за счет автоматизации. Многие проблемы возникают из-за того, что вы что-то пытаетесь сделать вручную. Человеческий фактор в on-premise «стреляет» чаще, чем в облаке, потому что облако закрывает эту проблему.
По данным 451 Research, финансовый эффект от ухода в облака:
- Снижение TCO на 57%. Только по персоналу затраты снижаются в два раза.
- ROI за 5 лет — 342%
- Дополнительного дохода в год 2,9 млн $
- Возврат инвестиций — 8 месяцев.
VK Cloud Big Data – масштабируемый облачный PaaS-сервис для анализа больших данных на базе Apache Hadoop, Apache Spark, ClickHouse
Ещё с конференции mailto:CLOUD





