
Подход Multicloud Native Service: что это такое и как поможет сделать IT-систему максимально отказоустойчивой
Если вы когда-либо работали с облачными сервисами, то наверняка знаете о распространенном мнении, что перенос приложения в облако является панацеей от всех возможных с ним проблем.
Я регулярно сталкиваюсь с такой позицией на встречах с самыми разнообразными заказчиками. К сожалению, это мнение ошибочно. Часть ответственности лежит и на самом клиенте.
Необходимо придерживаться определенных принципов в построении Cloud Native-приложений, чтобы обеспечить их отказоустойчивость, причем как на уровне программного кода, так и на уровне нижележащей инфраструктуры. При этом следует понимать, что даже соблюдение этих принципов не гарантирует полной защиты от всех рисков.
Поэтому если перед вами стоит задача построить на 100% отказоустойчивую и высокодоступную (High Availability, HA) систему, я рекомендую придерживаться подхода Multicloud Native Service, сочетающего лучшее в подходах Multicloud и Cloud Native. Такой подход не сводится только к использованию контейнеров: чтобы приложение могло пережить любой отказ, нужно подумать и об инфраструктуре, в частности использовать не одну, а минимум две независимые площадки, например провайдера публичного облака и частную инфраструктуру.
Я подробно расскажу о преимуществах и вариантах реализации этого подхода, о сложностях, с которыми можно столкнуться при его использовании, и методах их решения, а также о том, какими характеристиками должен обладать идеальный облачный провайдер.
Принципы построения Cloud Native-приложений
Прежде чем рассматривать варианты построения Cloud Native-архитектур, необходимо, чтобы ваши приложения были готовы к переносу в облако. По мнению фонда Cloud Native Computing Foundation (CNCF), ставшего своего рода амбассадором в области развития облачных технологий, существует пять базовых принципов, которые выделяют Cloud Native-приложения из числа прочих.
-
Динамичность
Это возможность быстрого развертывания и конфигурирования вашей системы на любой новой площадке, что становится особенно актуальным при неожиданной смене облачного провайдера. К средствам достижения динамичности можно отнести CI/CD и подход Infrastructure As Code (IaC). Остановимся подробнее на втором.
Вся ваша инфраструктура должна быть декларативно описана в виде кода. Описание может включать перечень необходимых сервису виртуальных машин, требования к их конфигурации, топологию сети, DNS-имена и так далее. Стандартом де-факто для решения этой задачи в последнее время стал Terraform, однако существуют и альтернативы: Ansible, Salt, Cloudify, Foreman, Pulumi, AWS Cloud Formation.
Задача этих инструментов — возможность быстрого развертывания, настройки инфраструктуры и контроль сохранения ее состояния, в том числе при смене провайдера. Если при небольшом количестве виртуальных машин их ручная настройка вполне возможна, то в том случае, когда это количество измеряется сотнями и дополняется сложной сетевой топологией, процесс переноса инфраструктуры может занять в лучшем случае несколько недель, а то и месяцев. Цель подхода IaC — сократить это время. При наличии декларативных описаний все, что обычно требуется при переходе, — это использовать другой Terraform-провайдер, изменить Environment-переменные и немного отформатировать код.
Хорошей практикой считается сочетание инструментов для декларативного описания с Post Install-скриптами, которые после запуска инфраструктуры конфигурируют информационную систему нужным образом, например устанавливают последние обновления используемого ПО и так далее. Для этой цели предназначены Ansible Playbooks, Puppet, Chef и другие инструменты, либо можно использовать cloud-unit.
-
Возможность эксплуатации
Это возможность управления жизненным циклом ваших систем в автоматизированном режиме. Это свойство тесно связано с динамичностью и включает в первую очередь применение пайплайнов CI/CD для автоматического развертывания приложений. У вас должна быть возможность оперативно выпускать новые сборки, отслеживать статус их выполнения на различных средах и выполнять откат в случае сбоев. Если вы строите приложение на основе микросервисов, для каждого сервиса рекомендуется настраивать независимый жизненный цикл (отдельную сборку). Обязательно учитывайте возможность отката обновлений или обновление только части ваших информационных систем (Rolling Update), это поможет избежать ошибок на уровне выкатки, которые могут привести к недоступности всего сервиса.
Современный IT-рынок предлагает множество решений для построения CI/CD: GitLab CI/CD, Jenkins, GoCD и другие.
-
Возможность наблюдения
Это мониторинг инфраструктуры и разнообразных бизнес-метрик ваших систем. Необходимость мониторинга для любого приложения, будь то Startup- или Enterprise-решение, сложно переоценить. Однако я регулярно сталкиваюсь с проектами, где мониторинг отсутствует, что в большинстве случаев приводит к серьезным проблемам. При переходе в облако мониторинг как минимум поможет проверять заявленный SLA провайдера и получать ретроспективу производительности при разборе спорных ситуаций, как максимум — находить узкие места в архитектуре и исправлять их до того, как они станут влиять на пользователей.
В большинстве случаев облачные провайдеры поддерживают все стандартные инструменты мониторинга, такие как Prometheus, Grafana, Fluentd, OpenTracing, Jaeger, Zabbix и другие, а также могут предлагать собственный встроенный мониторинг.
-
Эластичность
Это возможность масштабирования ваших приложений в зависимости от изменяющейся нагрузки. Когда речь заходит об автоматическом масштабировании, первым из доступных инструментов на ум приходит, конечно же, Kubernetes, ставший своего рода стандартом оркестрации контейнерных приложений. И действительно, он поддерживает все необходимые уровни масштабирования, а у некоторых провайдеров в том числе даже автомасштабирование на уровне кластера из коробки . Однако отмечу, что его использование отнюдь не является обязательным: можно построить эластичное приложение на основе чистого IaaS (Infrastructure as a Service), используя мониторинг и преднастроенные хуки для обработки изменений нагрузки. Да, Kubernetes значительно упрощает этот процесс, но не стоит забывать, что он является всего лишь инструментом.
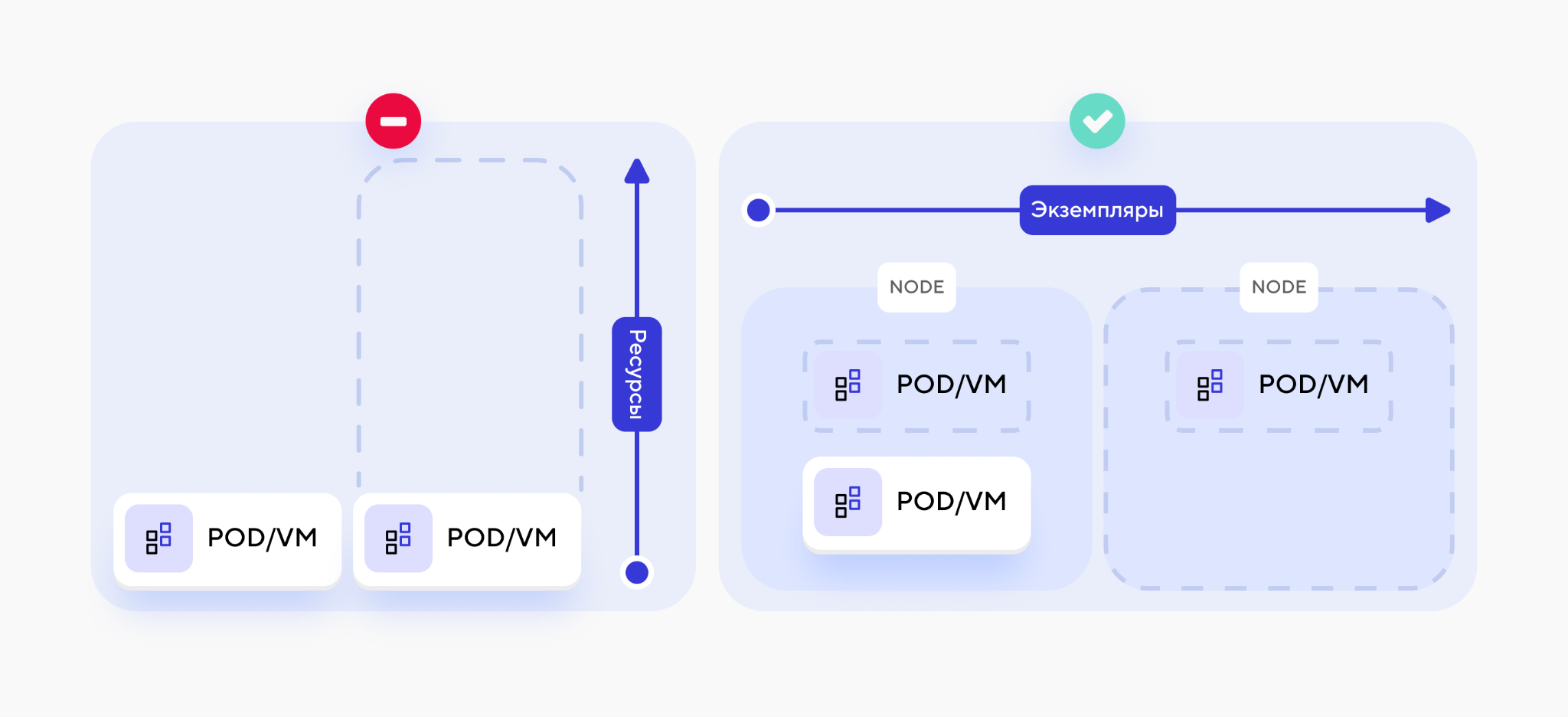
Чтобы соответствовать подходу Cloud Native, крайне важно планировать свою архитектуру так, чтобы в ней не было узлов, масштабируемых только вертикально (путем увеличения/уменьшения выделенных ресурсов), так как в конечном итоге вы будете ограничены мощностями нижележащего оборудования или гипервизоров в облаке. Постарайтесь обеспечить каждому узлу возможность горизонтального масштабирования — за счет изменения числа экземпляров самого приложения.

Отдавайте предпочтение горизонтальному масштабированию Также не стоит забывать оборотную сторону скейлинга — возможные проблемы с DDoS-атаками. Нужно всегда тщательно подбирать границы для автомасштабирования (минимальное и максимальное число узлов) и использовать AntiDDos. В противном случае DDoS-атаки, не отличаемые системой автомасштабирования от полезной нагрузки, могут привести вас к серьезным финансовым потерям.
-
Отказоустойчивость
Это возможность быстрого автоматического восстановления приложений в случае сбоев — с минимальным влиянием на пользователей. Несмотря на определенные гарантии от облачных провайдеров (SLA), нужно обязательно обеспечивать отказоустойчивость на уровне самих приложений и инфраструктуры.
Приведу несколько основных рекомендаций:
- Составьте план учений DRP (Disaster Recovery Plan) и регулярно проводите согласно нему стресс-тесты для выявления единых точек отказа в системе (Single Point Of Failure, SPOF). Очень важно учитывать все возможные домены отказа, в том числе проверяя поведение системы в боевом режиме — при выходе из строя отдельных узлов или целого плеча системы. Конечно, обеспечивая возможность их быстрого включения обратно.
- Используйте георепликацию для обеспечения высокой доступности ваших данных. Георепликация гарантирует хранение копий данных в нескольких дата-центрах. Но учитывайте, что геораспределенное хранилище имеет более высокие задержки отклика и не подходит для решений, требующих низкого Latency, например высоконагруженных баз данных.
- Используйте балансировку нагрузки на всех уровнях вашего приложения: перед web-серверами, серверами приложений и серверами баз данных. Все сетевые вызовы должны направляться не на прямые адреса виртуальных машин, а на адреса балансировщиков во избежание создания дополнительных точек отказа. Большинство облачных провайдеров предлагает балансировку нагрузки как сервис (Load Balancer as a Service, LBaaS). Учитывайте возможность выхода из строя части узлов, чтобы перераспределенная нагрузка не убила оставшиеся экземпляры сервиса. Используйте также надежные GSLB для балансировки между разными провайдерами.
- Используйте резервное копирование. Хотя я в своей практике сталкивался с примерами сервисов и информационных систем, где была построена правильная Cloud Native-архитектура и вовсе отказались от ведения бэкапов: они стали не актуальны. Так что ведение бэкапов желательно, но вовсе не обязательно — но только если вы грамотно используете Multicloud Native-подход. Если вы сомневаетесь, всегда делайте бэкапы!
- Проведите аудиты безопасности, например Penetration Test, на предмет уязвимостей и устойчивости к разным типам атак.
Виды рисков при работе с облаком
Предположим, ваш сервис или информационная система полностью соответствует описанным выше принципам Cloud Native-приложений. Вы выбрали подходящего провайдера и осуществили переход в облако с учетом всех рекомендаций. Означает ли это, что теперь вашим сервисам ничего не угрожает и возможность их недоступности полностью исключена? К сожалению, нет. Даже после переноса приложения в облако остаются определенные риски, которые условно можно разделить на три группы.
-
Географические риски
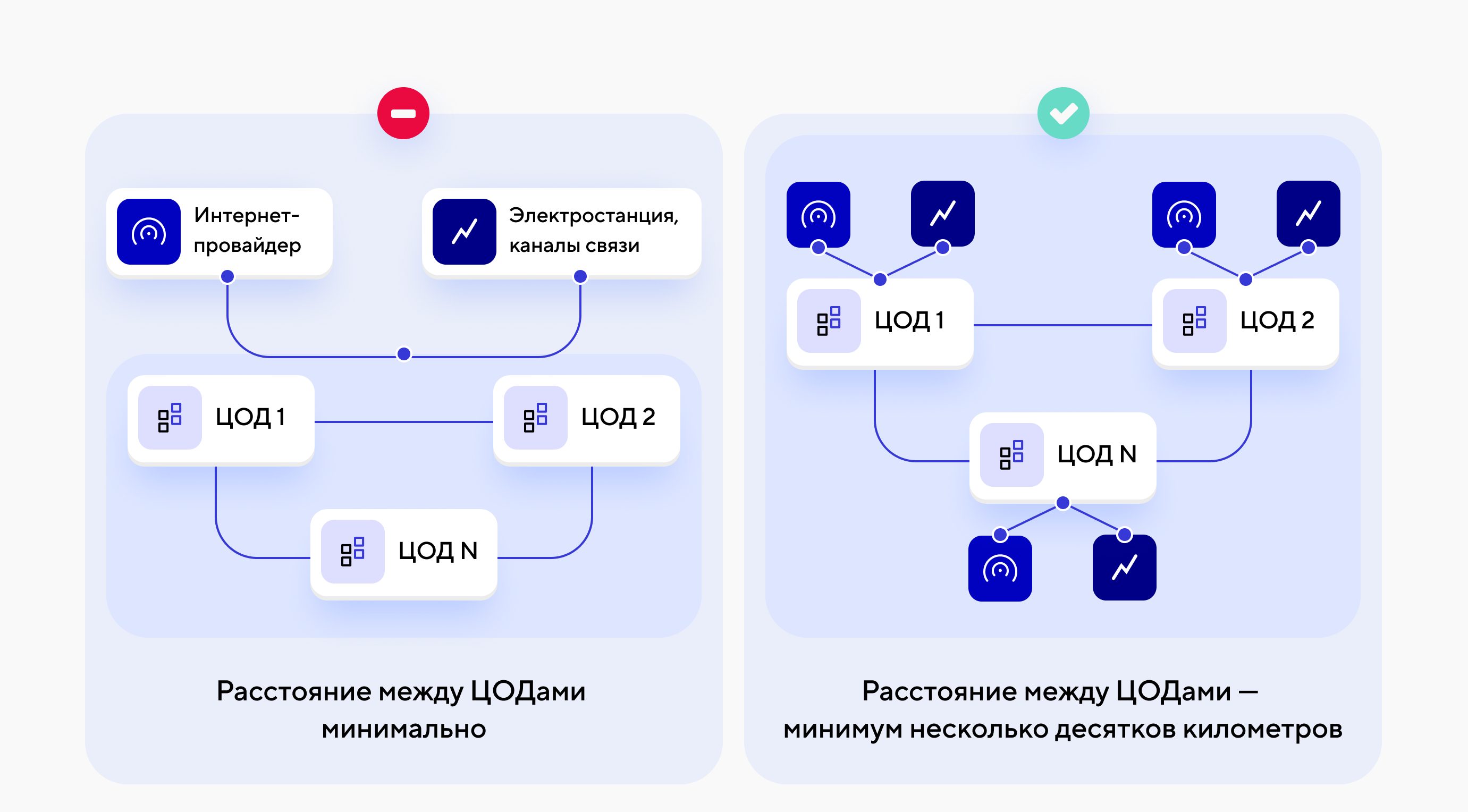
Любой, даже самый надежный облачный провайдер не застрахован от чрезвычайных ситуаций, будь то стихийные бедствия или аварии техногенного характера. Пожары, наводнения и даже банальная поломка кабеля — это лишь неполный перечень того, что может надолго вывести ЦОДы из строя, а в худшем случае полностью их уничтожить.
Думаю, многие помнят пожар в московском дата-центре OST провайдера DataLine в июне 2019-го. Но тогда удалось обойтись малыми жертвами — все клиенты были оперативно переведены на резервные площадки, да и урона машинному залу фактически нанесено не было: пострадали лишь кровля и система кондиционирования. К гораздо большим потерям привел недавний пожар в дата-центре SBG2 провайдера OVH в Страсбурге, обернувшийся падением множества сервисов по всему миру, полным уничтожением одного ЦОДа (SBG2) и вынужденной потерей второго ЦОДа, расположенного рядом и частично пострадавшего от пожара (SBG1). В этом как раз и состоит суть географических рисков: когда ЦОДы провайдера территориально расположены близко друг к другу, в случае катастрофы они не страхуют друг друга, а все оказываются под угрозой.
Поэтому при выборе провайдера обязательно обращайте внимание на два пункта:
- У провайдера несколько ЦОДов.
- ЦОДы расположены на достаточном расстоянии друг от друга, по возможности используют разные каналы связи, интернет-провайдеров и питаются от различных электростанций.
На что обратить внимание при выборе облачного провайдера для минимизации географических рисков -
Government-риски
Сюда входят различные политические и законодательные решения, которые могут неожиданно потребовать смены провайдера. В качестве наиболее яркого примера последних лет можно назвать бан социальной сети Parler в январе 2021 года, когда Amazon отказал этой платформе в дальнейшем хранении данных и приложение фактически стало недоступным. В России можно вспомнить 152-ФЗ, запрещающий хранить персональные данные пользователей за пределами РФ, что автоматически ограничивает выбор провайдеров для определенных организаций (банковский сектор, медицинские организации и так далее).
Особенность Government-рисков в том, что выход законопроектов и иных политических решений, как правило, требует очень быстрой реакции, поэтому крайне важно всегда быть готовым к незапланированной смене провайдера.
-
Риски сбоев на стороне провайдера
Это технические сбои на уровне провайдера в целом, чаще всего связанные с человеческим фактором, например выходом неверных обновлений, ошибками в прогнозировании потребляемых ресурсов и так далее. Даже у таких общепризнанных облачных лидеров, как Amazon и Google, регулярно фиксируются сбои в сервисах. Например, в Google Cloud за последний год произошло свыше 100 инцидентов, в AWS сбои происходят минимум раз в год. В качестве примера можно вспомнить крупный сбой на стороне AWS в ноябре 2020 года, в результате которого возникли неполадки в работе множества сайтов и приложений, включая iRobot, Flickr, Roku и Adobe Spark.
Очевидно, что даже самые надежные облачные решения не защищены от человеческих ошибок и не могут гарантировать стопроцентной доступности своих сервисов. Разумеется, провайдер должен обеспечивать заявленный уровень SLA и возмещать убытки в случае его нарушения, но вряд ли это компенсирует потерю вашего времени и потенциальных клиентов в случае долгосрочных сбоев.
Таким образом, мы рассмотрели три вида рисков, с которыми вы можете столкнуться после перевода своих приложений в облако. Но если первая группа рисков легко устраняется за счет выбора провайдера с географически разнесенными ЦОДами, то риски из второй и третьей групп, по моему мнению, можно исключить, только применив Multicloud Native Service-подход.

Multicloud Native Service и Multicloud: в чем разница?
В первую очередь следует различать подходы Multicloud и Multicloud Native Service.
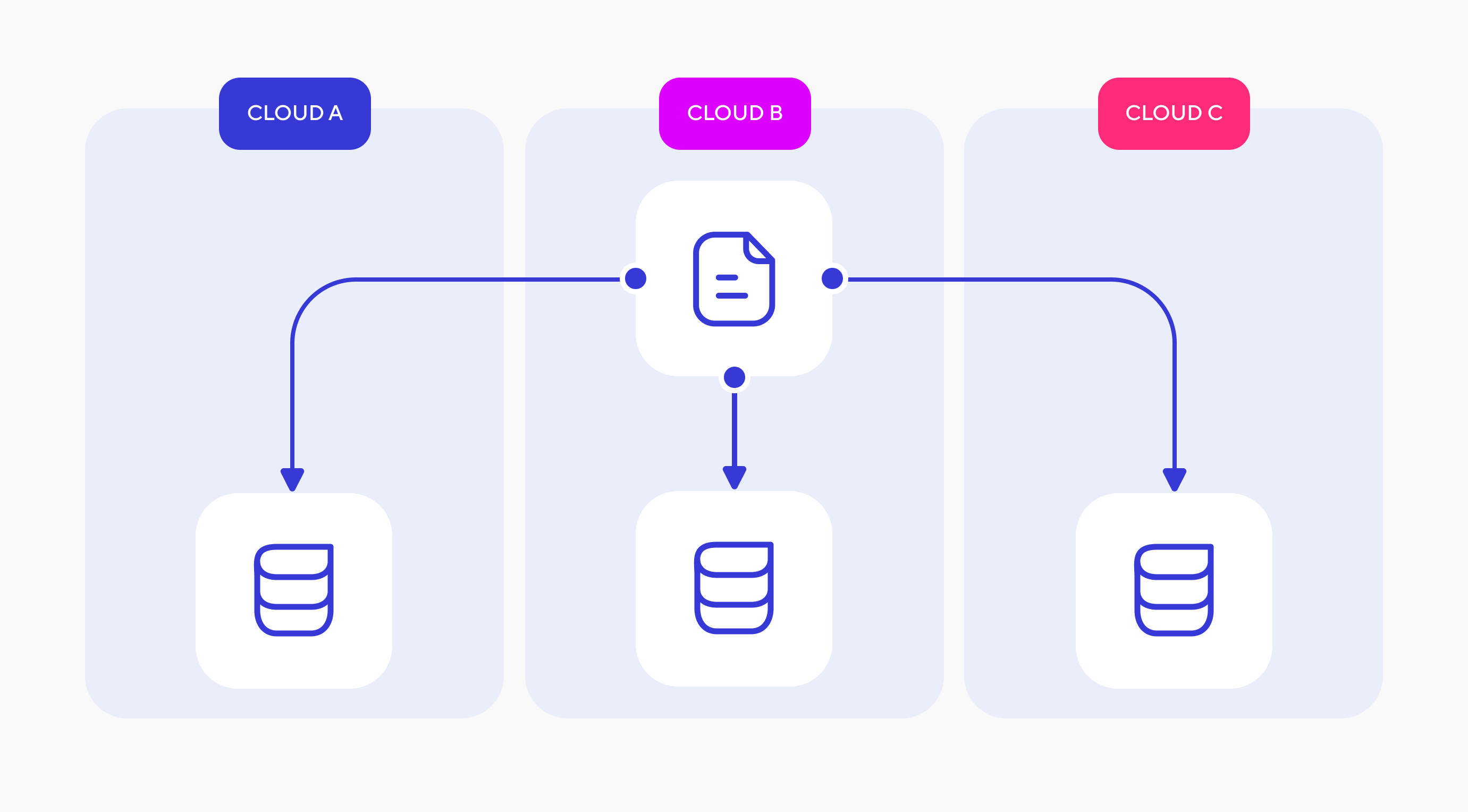
Multicloud предполагает наличие нескольких облачных провайдеров, но целью их совместного использования не обязательно является обеспечение максимальной отказоустойчивости ваших приложений.
Например, в силу ценовых или иных соображений вы можете использовать сервисы одного провайдера для сбора или хранения данных, а сервисы второго провайдера — для их анализа. Или вы можете использовать одно облако для работы основного приложения, а другие — исключительно для резервного хранения БД. В обоих случаях само приложение не обязательно развертывается во всех доступных облаках и, соответственно, не всегда соблюдается возможность переключения между облаками в случае сбоя.

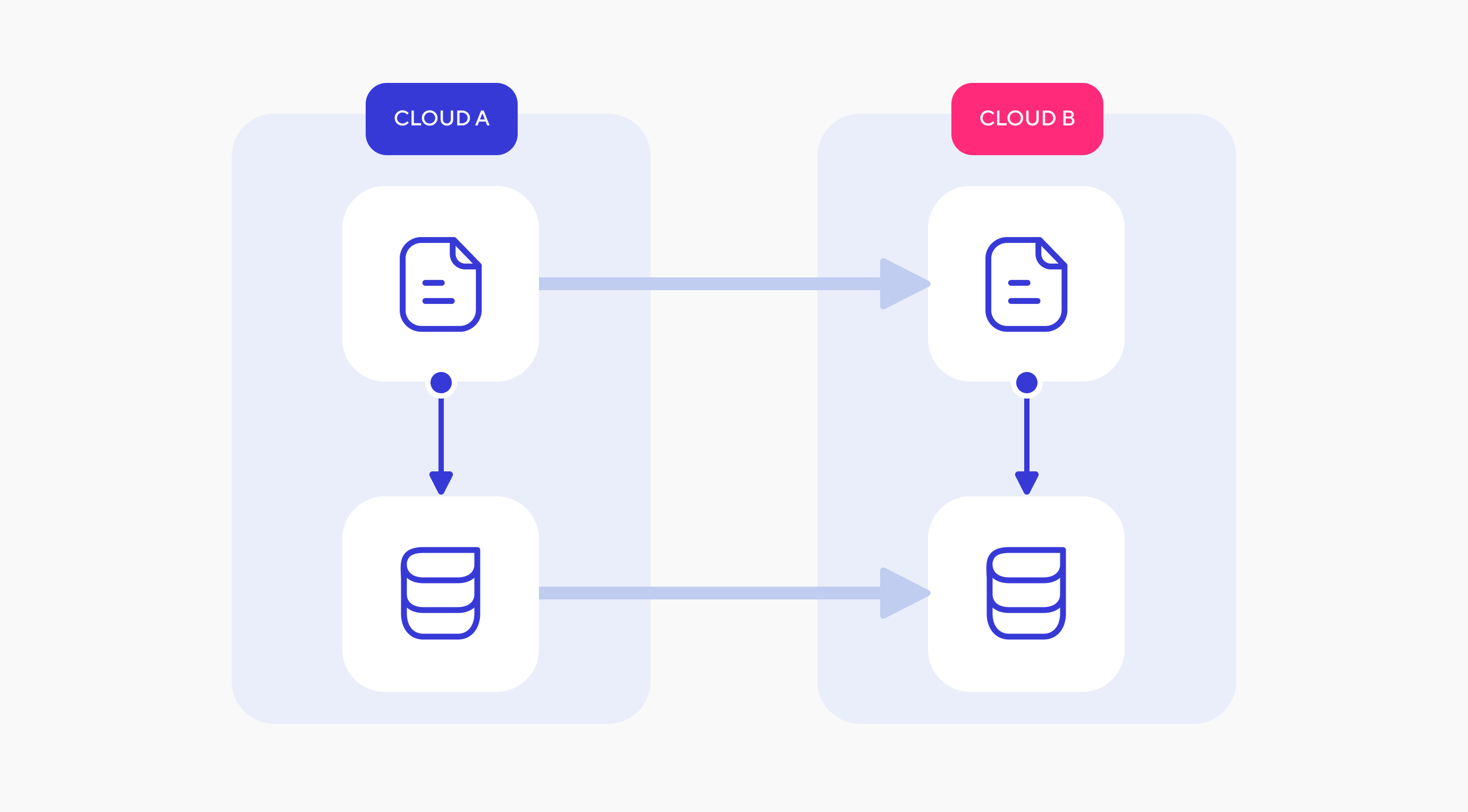
Подход Multicloud Native Service подразумевает, что вы разрабатываете свой продукт таким образом, что он соответствует принципам Cloud Native и полностью абстрагируется от конкретного облачного провайдера. В первую очередь это достигается за счет отказа от проприетарных сервисов, о которых мы еще подробно поговорим. Такой подход позволяет одновременно развертывать ваши приложения в нескольких выбранных вами облаках и легко переносить их из одного облака в другое без простоев.
Вы будете максимально застрахованы от рисков, о которых мы говорили выше: даже полный выход из строя одного из провайдеров не скажется на доступности вашей системы, ведь второй провайдер всегда сможет выступить в качестве страховки.
Таким образом, если Multicloud — это про количество облачных провайдеров, то Multicloud Native Service — это больше про сами приложения, их соответствие всем принципам Cloud Native и возможность развертывания на нескольких независимых площадках. Чаще всего Multicloud Native Service строится на основе Multicloud, но так происходит не всегда, так как в качестве площадок в этом случае могут выступать не только публичные облака или гибридные инфраструктуры, но и варианты с собственными ЦОДами компании.
Варианты построения архитектур Multicloud Native Service
Существует два основных способа построения архитектур по подходу Multicloud Native Service:
-
Использование нескольких публичных провайдеров
В этом случае одно плечо инфраструктуры строится на стороне одного публичного провайдера, а второе — на стороне другого провайдера. Например, можно комбинировать локального провайдера, действующего на территории РФ (VK, «Яндекс», МТС, «Ростелеком» и другие), и глобального, действующего во всем мире (AWS, Google Cloud, Alibaba, Azure и другие), либо использовать двух локальных провайдеров одновременно.
Я знаю крупные компании, которые сейчас пользуются услугами пары российских провайдеров, обеспечивая тем самым максимальную отказоустойчивость своих систем. Однако на практике полный отказ от собственной инфраструктуры в пользу публичных провайдеров используется довольно редко в силу дороговизны и недоверия клиентов к облаку. К услугам облачных провайдеров чаще всего обращаются разработчики стартап-решений, тогда как среднему и крупному бизнесу само решение о полном переходе в облако пока дается с трудом, особенно если речь идет о банковской и иных сферах с повышенными требованиями к безопасности. Поэтому чаще компании приходят к гибридным инфраструктурам.
-
Сочетание частной инфраструктуры и публичного провайдера
Это более распространенный вариант в российских реалиях, когда клиент продолжает использовать традиционную инфраструктуру на своей стороне (это может быть «голое железо», виртуализированная среда или даже приватное облако) плюс добавляет к ней публичного облачного провайдера. Чаще всего получившуюся архитектуру называют гибридным облаком (Hybrid), но если ПО и инфраструктура в этом случае реализуют все принципы Cloud Native-приложений, то систему в целом можно называть Multicloud Native Service.
Независимо от того, какую из двух схем вы примените на практике, в итоге вы получите максимально отказоустойчивую архитектуру, защищенную от всех видов рисков, рассмотренных выше. Даже полная потеря всех ЦОДов провайдера не приведет к остановке системы в целом, так как второе плечо продолжит функционировать.

Возможные проблемы при переходе на Multicloud Native Service и как их избежать
Разумеется, у подхода Multicloud Native Service есть свои подводные камни. Ниже приведен перечень наиболее часто встречающихся проблем и описаны способы их решения:
-
Сетевые задержки
Если для вашей системы приоритетны низкие задержки, например требуются синхронные реплики БД, то, скорее всего, вам не подойдет вариант сочетания локального и глобального провайдеров в силу их территориальной удаленности. Следует выбирать провайдеров, которые смогут обеспечить минимальный Latency, например через выделенный канал Direct Connect. Это могут быть два локальных провайдера на территории РФ либо сочетание локального облачного провайдера и частной инфраструктуры. Также Direct Connect позволяют делать некоторые глобальные провайдеры.
Если же для вашей системы не критично незначительное отставание в данных, измеряемое минутами, и допустимы асинхронные репликации, то использование глобальных провайдеров вполне возможно.
-
Разница в производительности вычислительных ресурсов
Сочетание различных провайдеров чревато тем, что мощность используемого в них оборудования будет сильно отличаться. Поэтому при выборе провайдера и последующей настройке конфигураций ВМ важно не допускать сильных расхождений в производительности ресурсов, используемых в разных плечах. Тип и частота процессоров, объем, пропускная способность и величина задержек на дисках, размер оперативной памяти — все эти и другие параметры должны быть примерно одинаковы. В противном случае обработка данных в двух плечах получится крайне неравномерной.
-
Vendor lock-in
Это привязка к сервисам определенного облачного провайдера, которая делает невозможной быструю смену провайдера при необходимости.
Пояснить проблему Vendor lock-in проще всего на примере референсных архитектур (Architecture Reference), предлагаемых большинством ведущих облачных провайдеров. Эти архитектуры описывают готовые решения (комбинации компонентов, их взаимосвязи и так далее) для типовых архитектурных задач, которые могут возникнуть при переходе в облако. Например, референсные архитектуры от Google и AWS.
На рисунке ниже приведен пример референсной архитектуры от AWS для обработки логов, которые впоследствии используются для построения мониторинга. Из рисунка очевидно, что для решения архитектурной задачи провайдер предлагает сразу несколько своих проприетарных сервисов: AWS Lambda, Amazon Kinesis Data Streams и так далее.
Пример референсной архитектуры от AWS. Источник Предположим, вы воспользовались рекомендациями провайдера, построили красивое и быстрое решение на основе его сервисов. Но что будет, если в будущем вам потребуется сменить провайдера? Правильно, многое придется переписывать с нуля. Вы потеряете время и, по сути, будет вынуждены делать двойную работу. А кроме этого, можете уступить конкурентам, которые, оказавшись в похожей ситуации, выполнят смену провайдера быстрее, если они не использовали проприетарные сервисы.

Это не означает, что референсные архитектуры вредны и в их использовании нет смысла. Напротив, их можно и нужно применять на практике, я сам очень часто к ним обращаюсь. Но всегда старайтесь избегать проприетарных сервисов и брать только общепринятые, присутствующие и у других провайдеров тоже. Эта рекомендация актуальна в том числе при использовании одного облачного провайдера.
Какому провайдеру отдать предпочтение
В предыдущих разделах мы определились, что для построения отказоустойчивых приложений лучше всего использовать пару различных облачных провайдеров. Но как сделать правильный выбор из множества доступных на современном IT-рынке вариантов, какие возможности предлагает идеальный провайдер? А также на какие сервисы стоит ориентироваться, чтобы не попасть в ловушку Vendor lock-in?
По моему мнению, джентльменский набор современного облачного провайдера должен выглядеть примерно так:
-
Реализация подхода IaC (Infrastructure as Code)
В большинстве случаев это подразумевает поддержку Terraform, но не обязательно. В VK Cloud (бывш. MCS) работает стандартный Terraform-провайдер, также можно использовать для управления инфраструктурой наш собственный Terraform-провайдер, доработанный под нашу платформу. Также сюда обязательно входит управление жизненным циклом виртуальных машин (Virtual Machine Lifecycle Management).
-
Наличие хорошо документированных CLI и API
Необходимо для быстрого и удобного управления облачными ресурсами.
-
Возможность подключения DC (Direct Connect)
Это установка выделенного сетевого соединения между облаком и своим собственным ЦОДом или офисом с целью изолированного сетевого соединения, а также увеличения пропускной способности и обеспечения более устойчивой работы, чем через подключение по интернету. При этом уровень, на котором настраивается соединение, не принципиален (L2, L3).
-
Поддержка CDN (Content Delivery Network)
Использование географически распределенной сетевой инфраструктуры, лежащей в основе CDN, позволяет быстро раздавать контент по всему миру с задержкой в считанные миллисекунды даже во время пиковых нагрузок.
-
Наличие DNS и балансировщиков сетевой нагрузки
Это важная часть настройки любых виртуальных сетей.
-
Соответствие местному законодательству и наличие прочих сертификатов
Например PCI DSS, ISO 27*, GPDR для Европы, ФСТЭК для России и так далее. Это поможет избежать дополнительной головной боли при локализации.
-
Технологическое соответствие между провайдерами
Если, например, ваша исходная инфраструктуру использует VMWare, логично выбрать провайдера предоставляющего гипервизор ESXi, желательно той же версии. Это сильно упростит миграцию. Тоже справедливо и для других платформ и гипервизоров. Требование не является обязательным, можно разместиться и на разных платформах.
-
Поддержка основного пула сервисов
- контейнеризация/оркестрация (общепризнанный стандарт K8s или OpenShift);
- базы данных как сервис;
- S3 — объектное хранилище для хранения больших объемов данных и статического контента;
- очереди сообщений (Simple Queue Service, SQS);
- Big Data — с этим сервисом стоит быть аккуратным, чтобы не получить Vendor lock-in, так как некоторые провайдеры реализуют его по-своему;
- мониторинг инфраструктуры и бизнес-метрик, в идеале сервис мониторинга должен быть независимым;
- бессерверные вычисления (Function as a Service, FaaS). Незаменимы для обработки непрогнозируемой нагрузки без сохранения состояния (чат-боты, социальные сети и так далее);
- аудит как сервис;
- стандартные функции вида биллинга, сервисов ИБ (такие как WAF, AntiDDOS, возможность проведения аудитов ИБ), возможности использовать idP, RBAC;
- Выбирайте надежный Global Server Load Balancer, не надейтесь только на балансировку на уровне облачного провайдера, так как она подвержена тем же рискам.


Выводы
Кто-то скажет, что это давно известно, и будет прав. Однако встречаемое мною каждый день среди совсем разных бизнесов, компаний и IT-специалистов ошибочное мнение, что облако должно обеспечивать доступность вашего приложения, побудило во мне желание еще раз напомнить, что отказоустойчивость и доступность приложения — это общая задача.
Если для ваших приложений приоритет — отказоустойчивость и высокая доступность, лучшим решением будет использовать подход Multicloud Native Service. Да, это сложно, дорого, требует новых подходов к разработке, применимо не ко всем типам сервисов и чаще всего доступно исключительно крупному бизнесу. Но это позволяет исключить все виды возможных рисков.
Если же вы не готовы пойти по этому пути или у вас пока нет высоких требований к отказоустойчивости, можно для начала остановиться на одном провайдере, это покроет большую часть рисков. Но даже в этом случае стоит помнить о принципах построения Cloud Native-приложений, следить за отказоустойчивостью (как на уровне программного кода, так и на уровне инфраструктуры) и стараться избегать проприетарных сервисов, чтобы потенциальная смена провайдера в будущем могла пройти максимально быстро и безболезненно.
Также важно понимать, что подходы Cloud Native и построенный на его основе Multicloud Native Service — это в большей степени не про используемые вами программные инструменты. Например, они не требуют от вас жесткого использования контейнеров и Kubernetes, как принято считать. Применение этих подходов в первую очередь означает, что вы полностью продумали инфраструктуру и проверили все возможные домены отказа. И в случае сбоев вы не возлагаете всю ответственность на своего провайдера, осознавая, что успешная работа приложений в облаке во многом определяется и вашими действиями тоже.
Любите облака, и они ответят вам взаимностью.




