Installing and configuring ELK, collecting, analyzing and visualizing logs
This scenario requires an installed and configured server for ELK on Ubuntu 18.04 LTS x86_64.

The ELK stack consists of three components:
- Elasticsearch — an engine for storing, indexing and processing data in a shared storage, as well as for full-text data search.
- Logstash — a utility for collecting, filtering, aggregating, changing and then redirecting the source data to the final storage.
- Kibana — a web interface for viewing and analyzing data from the repository.
- Login to the Ubuntu server as root.
- Import the Elasticsearch repository key:
root@ubuntu-std1-1:~# wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt key add -OK
- Install apt-transport-https:
root@ubuntu-std1-1:~# apt-get install apt-transport-https
- Add a repository:
root@ubuntu-std1-1:~# echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.listdeb https://artifacts.elastic.co/packages/7.x/apt stable main
- Install Elasticsearch:
root@ubuntu-std1-1:~# apt-get update && apt-get install elasticsearch
- Install Kibana:
root@ubuntu-std1-1:~# apt-get install kibana
- Install OpenJDK for Logstash to work:
root@ubuntu-std1-1:~# apt-get install openjdk-8-jre
- Install Logstash:
root@ubuntu-std1-1:~# apt-get install logstash
Elasticsearch is configured using three configuration files:
- elasticsearch.yml — main configuration file;
- jvm.options — file for configuring a Java machine to run Elasticsearch;
- log4j2.properties — file to configure Elasticsearch logging.
jvm.options
The most important thing in this file is the setting of the memory allocated for the JVM (Heap Size). For Elasticsearch, this parameter directly affects how large data arrays it can process. Heap Size is determined by a couple of parameters:
- Xms — initial value;
- Xmx — maximum value.
The default Heap Size is 1 GB. If the amount of memory on the server allows, increase this value (more about Heap Size). To do this, find the lines:
Xms1gXmx1g
and replace them, for example, with the lines:
Xms4gxmx4g
log4j2.properties
For convenience, you can change appender.rolling.policies.size.size, which specifies the size of the log at which rotation is performed (default is 128 MB). More about logging see here.
elasticsearch.yml
Customize:
node.name: elasticsearch— specify the name of the node;network.host: 127.0.0.1— set to listen only to localhost.
Start elasticsearch:
root@ubuntu-std1-1:~# systemctl start elasticsearch.service
If you specify too large a Heap Size value, the launch will fail. In this case, the following will be in the logs:
root@ubuntu-std1-1:~# systemctl start elasticsearch.serviceJob for elasticsearch.service failed because the control process exited with error code.See "systemctl status elasticsearch.service" and "journalctl -xe" for details.root@ubuntu-std1-1:~# journalctl -xe-- Unit elasticsearch.service has run starting up.Nov 12 12:48:12 ubuntu-std1-1 elasticsearch[29841]: Exception in thread "main" java.lang.RuntimeException: starting java failed with [1]Nov 12 12:48:12 ubuntu-std1-1 elasticsearch[29841]: output:Nov 12 12:48:12 ubuntu-std1-1 elasticsearch[29841]: #Nov 12 12:48:12 ubuntu-std1-1 elasticsearch[29841]: # There is insufficient memory for the Java Runtime Environment to continue.Nov 12 12:48:12 ubuntu-std1-1 elasticsearch[29841]: # Native memory allocation (mmap) failed to map 986513408 bytes for committing reserved memory.Nov 12 12:48:12 ubuntu-std1-1 elasticsearch[29841]: # An error report file with more information is saved as:Nov 12 12:48:12 ubuntu-std1-1 elasticsearch[29841]: # /var/log/elasticsearch/hs_err_pid29900.log
If successful, add Elasticsearch to the list of processes to start automatically:
root@ubuntu-std1-1:~# systemctl enable elasticsearch.serviceSynchronizing state of elasticsearch.service with SysV service script with /lib/systemd/systemd-sysv-install.Executing: /lib/systemd/systemd-sysv-install enable elasticsearchCreated symlink /etc/systemd/system/multi-user.target.wants/elasticsearch.service → /usr/lib/systemd/system/elasticsearch.service.
Verify that Elasticsearch is responding:
root@ubuntu-std1-1:~# curl http://localhost:9200{"name" : "ubuntu-std1-1","cluster_name" : "elasticsearch","cluster_uuid" : "ZGDKK_5dQXaAOr75OQGw3g","version" : {"number" : "7.4.2","build_flavor" : "default","build_type" : "deb","build_hash" : "2f90bbf7b93631e52bafb59b3b049cb44ec25e96","build_date" : "2019-10-28T20:40:44.881551Z","build_snapshot" : false,"lucene_version" : "8.2.0","minimum_wire_compatibility_version" : "6.8.0","minimum_index_compatibility_version" : "6.0.0-beta1"},"tagline" : "You Know, for Search"}
By default, the Kibana configuration file /etc/kibana/kibana.yml contains all the necessary settings. The only setting you need to change is server.host: "localhost". By default, Kibana is only available locally. To access Kibana remotely, replace “localhost” with the external IP address of the server where Kibana is installed. Also, if Elasticsearch is not on the same host as Kibana, change the elasticsearch.hosts setting: ["http://localhost:9200"].
- Start Kibana:
root@ubuntu-std1-1:/etc/kibana# systemctl start kibana.service
- Add Kibana to the list of applications that start automatically:
root@ubuntu-std1-1:/etc/kibana# systemctl enable kibana.serviceSynchronizing state of kibana.service with SysV service script with /lib/systemd/systemd-sysv-install.Executing: /lib/systemd/systemd-sysv-install enable kibana
- In a browser, navigate to http://
:5601.
If Kibana is running, the following will be displayed:

By default, Elasticsearch and Kibana are fully accessible to everyone. Access can be restricted in one of the following ways:
- Use Nginx as a reverse proxy with authorization and access control.
- Use the built-in elasticsearch mechanism xpack.security (for details see here or [here](https ://www.elastic.co/guide/en/kibana/current/using-kibana-with-security.html)).
Consider the most popular first method.
- Install Nginx:
root@ubuntu-std1-1:~# apt-get install nginx
- Make sure that in the configuration file /etc/elasticsearch/elasticsearch.yml the network.host parameter is set to 127.0.0.1 or localhost. If necessary, make this configuration and restart the elasticsearch daemon:
root@ubuntu-std1-1:~# cat /etc/elasticsearch/elasticsearch.yml | grep network.hostnetwork.host: 127.0.0.1root@ubuntu-std1-1:~# systemctl restart elasticsearch.service
- Make sure that the server.host parameter in the configuration file /etc/kibana/kibana.yml is set to 127.0.0.1 or localhost. If necessary, make this configuration and restart the kibana daemon:
root@ubuntu-std1-1:~# cat /etc/kibana/kibana.yml | grep server.hostserver.host: "127.0.0.1"# When this setting's value is true Kibana uses the hostname specified in the server.hostroot@ubuntu-std1-1:~# systemctl restart kibana.service
- Make sure Elasticsearh and Kibana are using interface 127.0.0.1:
root@ubuntu-std1-1:~# netstat -tulpn | grep9200tcp6 0 0 127.0.0.1:9200 :::\* LISTEN 10512/javaroot@ubuntu-std1-1:~# netstat -tulpn | grep 5601tcp 0 0 127.0.0.1:5601 0.0.0.0:\* LISTEN 11029/node
- In /etc/nginx/sites-available create a kibana.conf file and add the following to it:
server {listen <external IP address of the server with Kibana and Nginx>:5601;server_name kibana;error_log /var/log/nginx/kibana.error.log;access_log /var/log/nginx/kibana.access.log;location / {auth_basic "Restricted Access";auth_basic_user_file /etc/nginx/htpasswd;rewrite ^/(.\*) /$1 break;proxy_ignore_client_abort on;proxy_pass http://localhost:5601;proxy_set_header X-Real-IP $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;proxy_set_header Host $http_host;}}
- Specify the username (USER) and password (PASSWORD):
root@ubuntu-std1-1:/etc/nginx# printf "USER:$(openssl passwd -crypt PASSWORD)\n" >> /etc/nginx/htpasswd
- To enable the site, create a symlink to the /etc/nginx/sites-enabled folder:
root@ubuntu-std1-1:~# ln -s /etc/nginx/sites-available/kibana.conf /etc/nginx/sites-enabled/kibana.conf
- Start Nginx:
root@ubuntu-std1-1:~# systemctl start nginx
- In a browser, navigate to http://
:5601. In the window that opens, enter your login and password to access the Kibana web interface.
Similarly configure Nginx as a reverse proxy for Elasticsearh (port 9200) and Logstash (typically port 5044).
To get familiar with Kibana, you can use the test dataset:

Beats is part of the Elasticsearch infrastructure, the so-called Data Shippers (data providers). These are lightweight agents that take data from various sources and transform it for transmission to Elasticsearch. The functionality of Beats partially duplicates Logstash, but Beats is lighter, easier to set up, works faster and does not require the Java stack to be installed. Typically, the nodes where the logs are generated have the appropriate Beats agents installed, which transfer the logs to Logstash. Logstash aggregates, transforms logs and passes them to Elasticsearch. There are many different Beats, the standard set includes the following agents:
- Filebeat — collection of logs from various log files.
- Packetbeat — collection of network statistics.
- Winlogbeat — collection of logs on the Windows platform.
- Metricbeat — collection of various metrics.
- Heartbeat — collection of data on infrastructure availability.
- Auditbeat — collection of system audit data.
- Functionbeat — data collection from Serverless projects (AWS Lambda).
- Journalbeat — collection of Journald logs.
The most common agent is Filebeat, we use it to collect Nginx logs.
- Install Filebeat:
root@ubuntu-std1-1:~# apt-get install filebeat
- Allow Nginx log processing:
root@ubuntu-std1-1:~# mv /etc/filebeat/modules.d/nginx.yml.disabled /etc/filebeat/modules.d/nginx.yml
If the logs are in a non-standard location, or only part of the logs needs to be processed, uncomment and fill in the var.paths variables in the /etc/filebeat/modules.d/nginx.yml file.
In the example below, we will collect and analyze logs for accessing the Kibana service. When configuring Nginx, we specified that access logs would be stored in the /var/log/nginx/kibana.access.log and /var/log/nginx/kibana.error.log files.
- Make the /etc/filebeat/modules.d/nginx.yml file look like this:
# Module: nginx# Docs: https://www.elastic.co/guide/en/beats/filebeat/7.4/filebeat-module-nginx.html-module: nginx# Access logsaccess:enabled: true# Set custom paths for the log files. if left empty,# Filebeat will choose the paths depending on your OS.var paths:- /var/log/nginx/kibana.access.log# Error logserror:enabled: true# Set custom paths for the log files. if left empty,# Filebeat will choose the paths depending on your OS.var paths:- /var/log/nginx/kibana.error.log
- In the /etc/filebeat/filebeat.yml file, edit the setup.kibana section:
setup.kibana:host: "<IP address of server with Kibana>:5601"username: "login"password: "password"
- The logs will be sent to Logstash, so comment out the output.elasticsearch section and specify the IP address of the server hosting Logstash in the output.logstash section:
#-------------------------- Elasticsearch output --------------------- ---------#output.elasticsearch:# Array of hosts to connect to.# hosts: ["localhost:9200"]# Optional protocol and basic auth credentials.#protocol: "https"#username: "elastic"#password: "changeme"#---------------------- Logstash output ------------------ -------------output.logstash:# The Logstash hostshosts: ["<logstash server IP address>:5044"]# Optional SSL. By default is off.# List of root certificates for HTTPS server verifications#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]# Certificate for SSL client authentication#ssl.certificate: "/etc/pki/client/cert.pem"# Client Certificate Key#ssl.key: "/etc/pki/client/cert.key"
- Make sure there are no errors in the configuration file:
root@ubuntu-std1-1:/etc/filebeat# filebeat test config -c /etc/filebeat/filebeat.ymlconfig OK
Before starting Filebeat, configure Logstash to accept logs.
The Logstash configuration file generally consists of three sections:
- input — description of the destination of the logs.
- filter — transformation of logs.
- output — description of the destination of the converted logs.
- Create a file /etc/logstash/conf.d/input-beats.conf containing the port number on which Beats (in particular, Filebeat) sends its logs:
input {beat {port => 5044}}
- Create the /etc/logstash/conf.d/output-elasticsearch.conf file and specify that logs should be sent to Elasticsearch at localhost and indexes should be named in the nginx-
format (that is, a new index will be created every day , which is convenient for analysis):
output {elasticsearch {hosts => [ "localhost:9200" ]manage_template => falseindex => "nginx-%{+YYYY.MM.dd}"}}
- Create a file /etc/logstash/conf.d/filter-nginx.conf with the following content:
filter {if [event][dataset] == "nginx.access" {grok {match => [ "message" , "%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] \"(?:%{WORD:verb} %{ NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})\" %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:referrer } %{QS:user_agent}"]overwrite => [ "message" ]}mutate {convert => ["response", "integer"]convert => ["bytes", "integer"]convert => ["responsetime", "float"]}geoip {source => "clientip"target => "geoip"add_tag => ["nginx-geoip"]}date {match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]remove_field => [ "timestamp" ]}useragent {source => "user_agent"}}}
Filebeat, which will send Nginx logs to Logstash, writes the entire Nginx log line in the message field. Therefore, this field needs to be parsed into variables that can be worked with in Elasticsearch. This parsing is done in the grok section of the NGINX ACCESS LOG format.
In the mutate section, you can change the data storage format (for example, so that the bytes field from the log is stored as a number, not as a string).
In the geoip section, geolocation fields are added to the log by the request IP address.
The date section is used to parse the query date field from the log and convert it to pass it to Elasticsearch.
The useragent section fills in the fields according to the field from the log. Note that the agent field is usually used in these tutorials. This field will not work with Filebeat + Logstash as it is intended to be used when writing directly from Filebeat to Elasticsearh. When used in Logstash, an error will be thrown:
[2019-11-19T09:55:46,254][ERROR][logstash.filters.useragent][main] Uknown error while parsing user agent data {:exception=>#<TypeError: cannot convert instance of class org.jruby.RubyHash to class java.lang.String>, :field=>"agent", :event=>#<LogStash::Event:0x1b16bb2>}
For the same reason, you don't need to use the %{COMBINEDAPACHELOG} macro in the grok match section.
To track errors in Logstash, enable debugging. To do this, add the following line to the output section:
stdout { codec => rubydebug }
As a result, the output to the Elasticsearch database will be duplicated by the output to the console/syslog. It is also useful to use the Grok Debugger to test grok match expressions.
- Launch Logstash and add it to the list of applications to start automatically:
root@ubuntu-std1-1:~# systemctl start logstashroot@ubuntu-std1-1:~# systemctl enable logstashCreated symlink /etc/systemd/system/multi-user.target.wants/logstash.service → /etc/systemd/system/logstash.service.
- Make sure the service has started:
root@ubuntu-std1-1:~# netstat -tulpn | grep5044tcp6 0 0 :::5044 :::\* LISTEN 18857/java
- Test Filebeat:
root@ubuntu-std1-1:~# service filebeat start
After starting Filebeat, Kibana access logs go to Logstash, then to Elasticsearch. To view these logs, Kibana needs to configure templates.
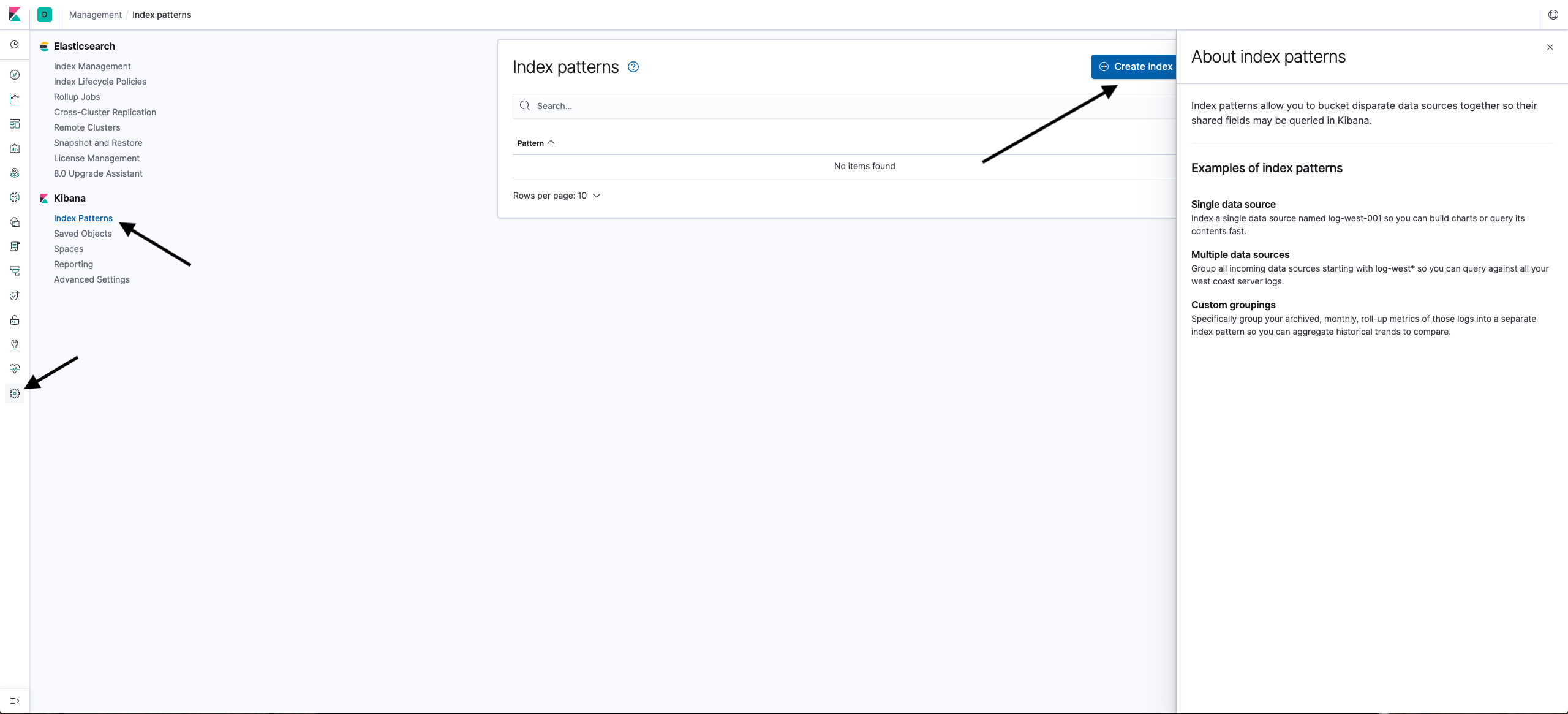
- Go to Kibana, click the gear in the left menu, select Kibana > Index Patterns and click Create Index Pattern.
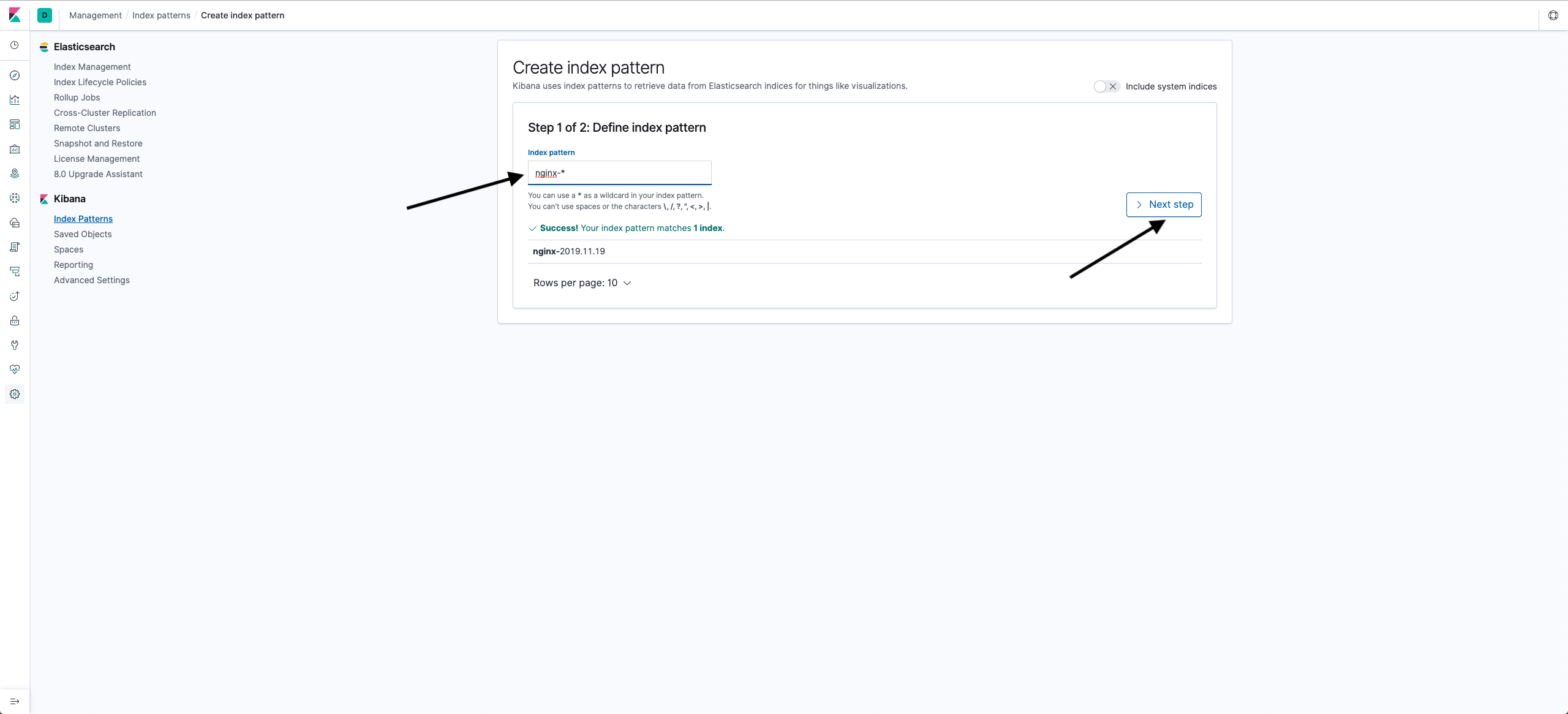
- To select all entries, enter nginx-* in the Index pattern field and click Next step.
- To use timestamps from log files, select @timestamp in the Time Filter field name and click Create index pattern.
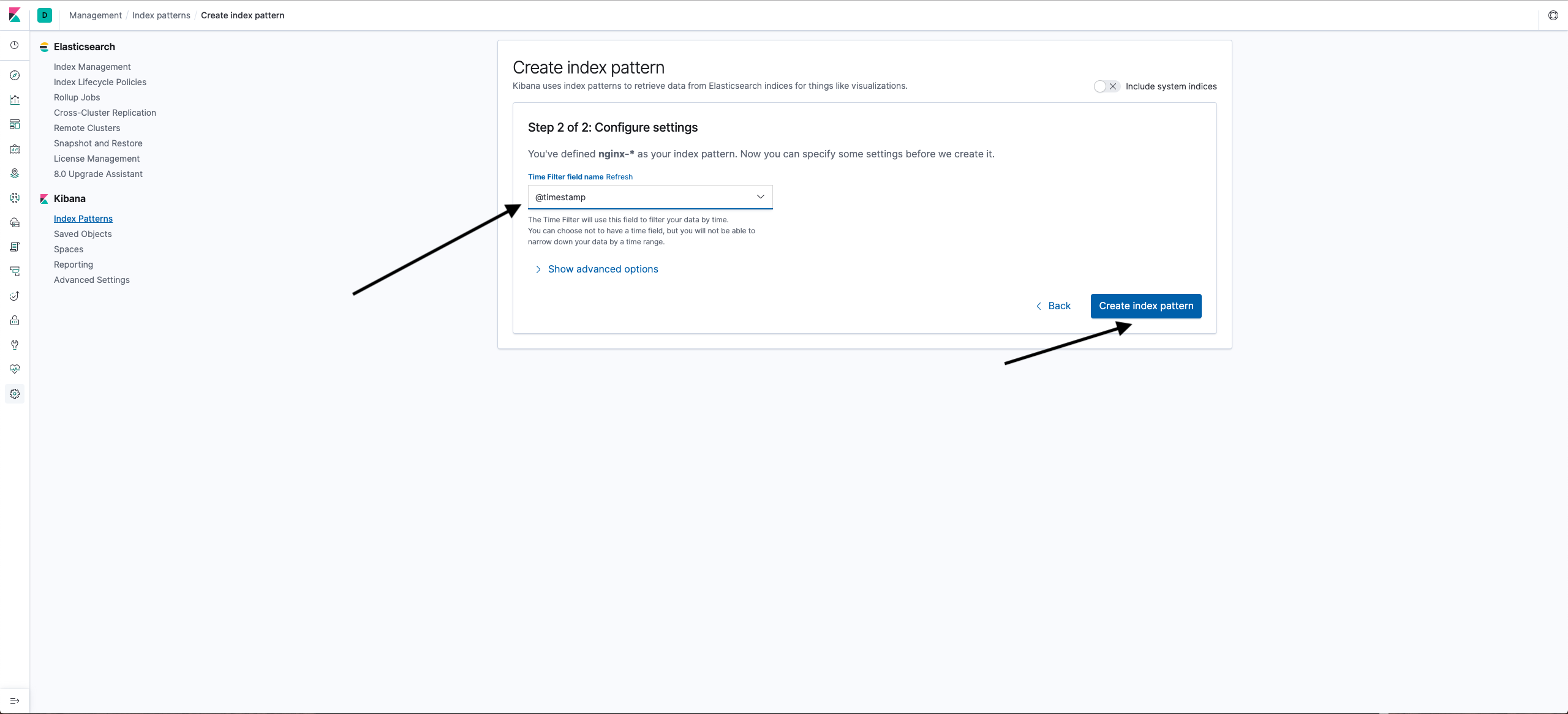
An index pattern will be created.
To see the logs that got into Elasticsearch, go to Discover.
The dashboard in Kibana is made up of visualizations. A visualization is a kind of graph built on specific queries from Elasticsearch.
Let's build the first visualization - top 10 clients.
- Select Visualizations from the left menu and click the Create new visualization button.

- Select Vertical bar.

- Select the nginx-* template.

- Add an X axis.
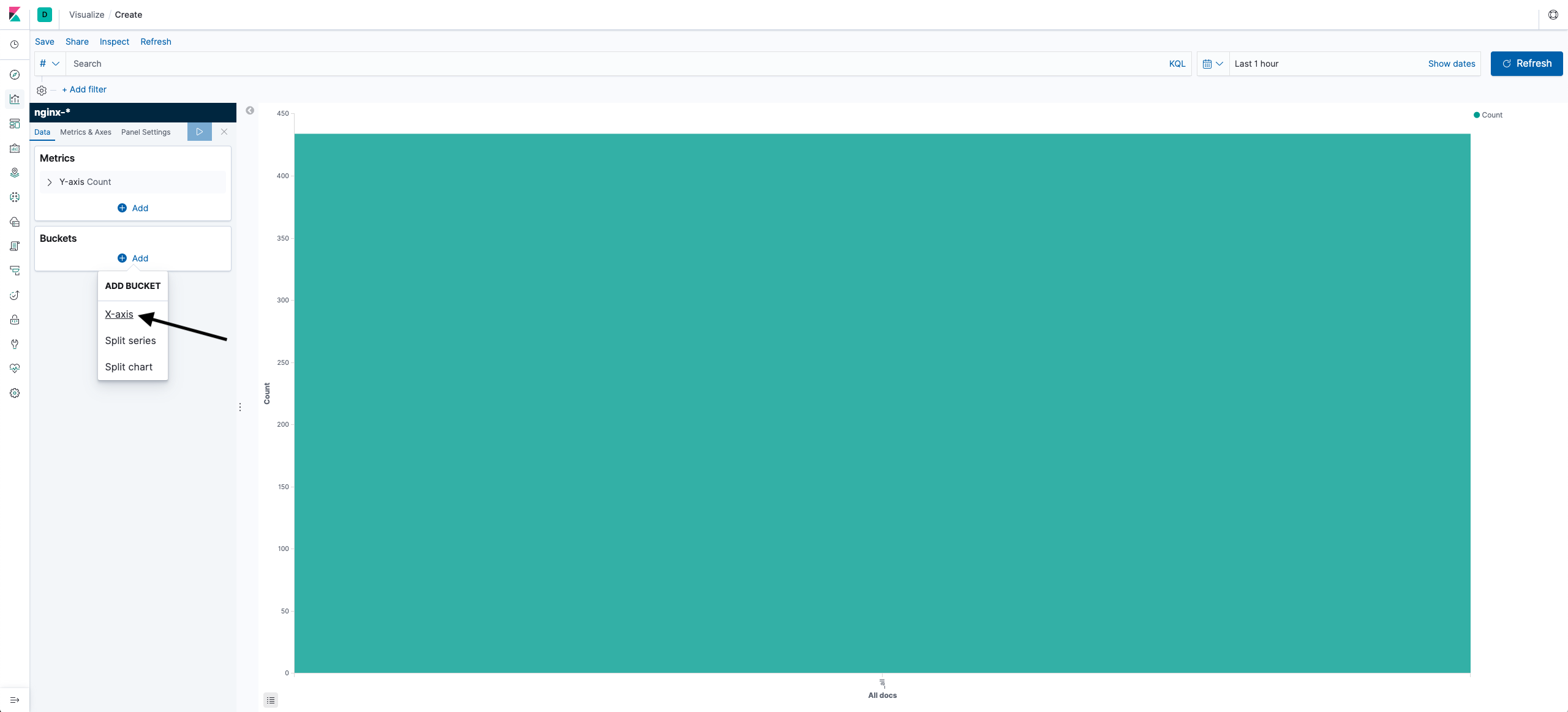
- Enter data:
- Aggregation: Terms — returns the specified number of top values.
- Field: clientip.keyword — select a client by IP address.
- Size: 10 — 10 top values.
- Custom Label: Top 10 clients — the name of the visualization.

- Run the query and save the visualization.
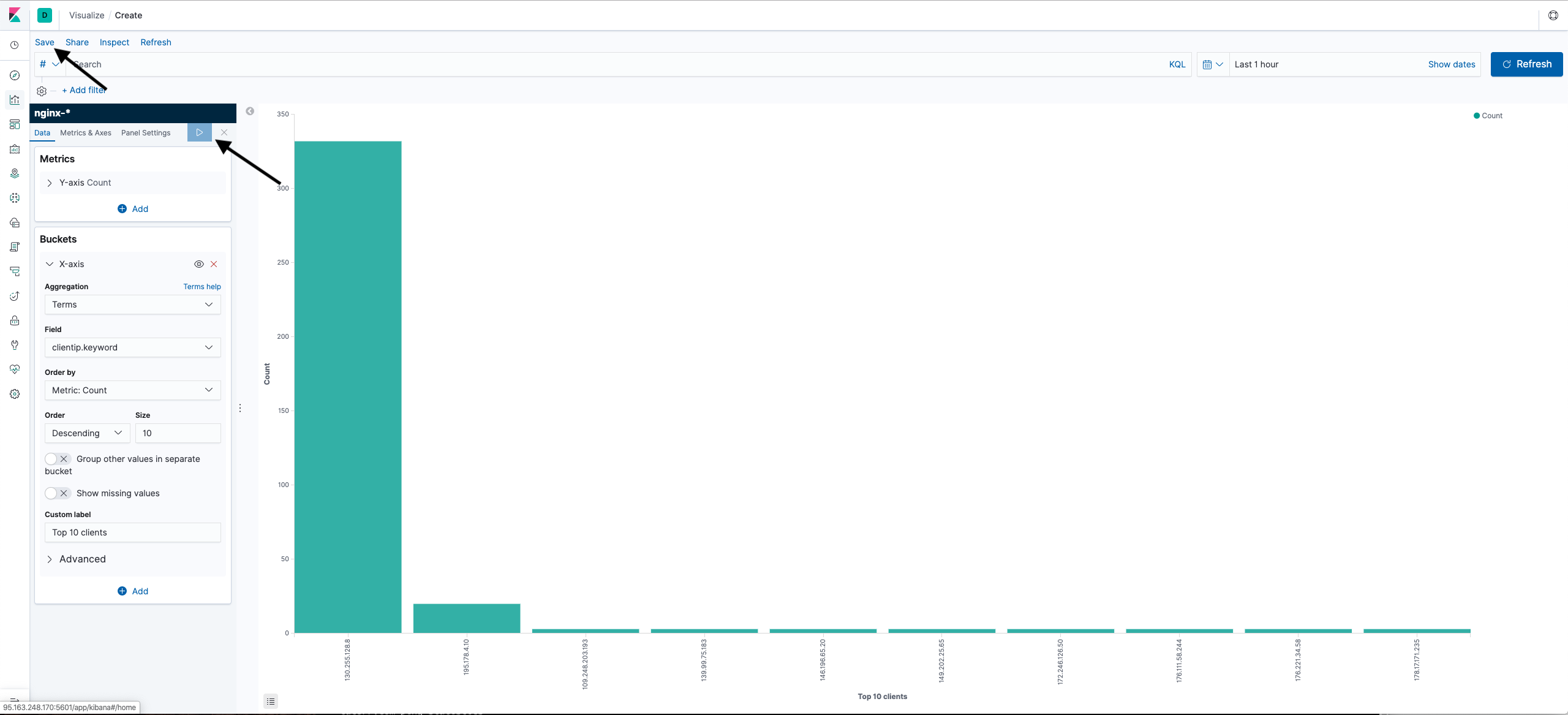
As a result, the visualization shows the top 10 IP addresses from which requests were made.
Let's build a second visualization - a pie chart showing the top 5 countries from which users contacted.
- Select Visualizations from the left menu and click the Create new visualization button.
- Select Pie.
- Select the nginx-* template.
- Add an X axis.
- To display data in slices, select Add bucket / Split slices.

- Enter the following data:
- Aggregation: Terms — select the top data value.
- Field: geoip.country_code2.keyword — two-letter country code.
- Size:5 — select top 5.
- Custom label: Top 5 countries — chart title.

- Run the query and save the visualization.

The graph will display the top 5 countries from which there was access.
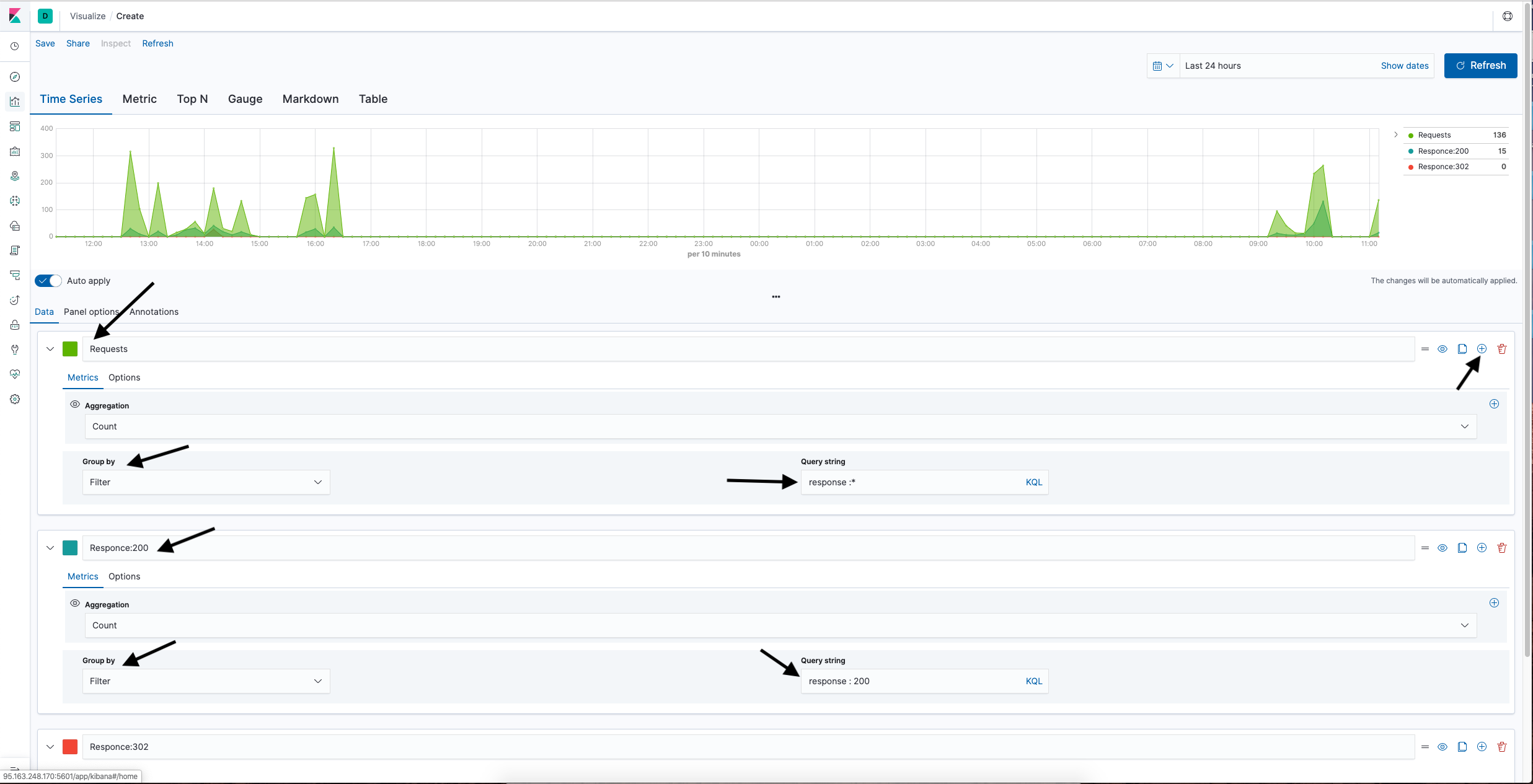
Let's build the third visualization - a graph of the number of requests, divided by response codes.
- Select Visualizations from the left menu and click the Create new visualization button.
- Select TSVB.
- Select the nginx-* template.
- To get all server response codes (that is, all requests sent to the server), in the window that appears, enter Requests in the name, select group by filter, and specify response:* in the query string.
- To add a second line to the chart, .
- To get a sample of the number of server responses "200 OK" per unit of time on the second chart, click "+", select a different color, specify Responce:200 in the title, response:200 in the query string.
- Click "+" and add the 302 response code in the same way. Then save the visualization.
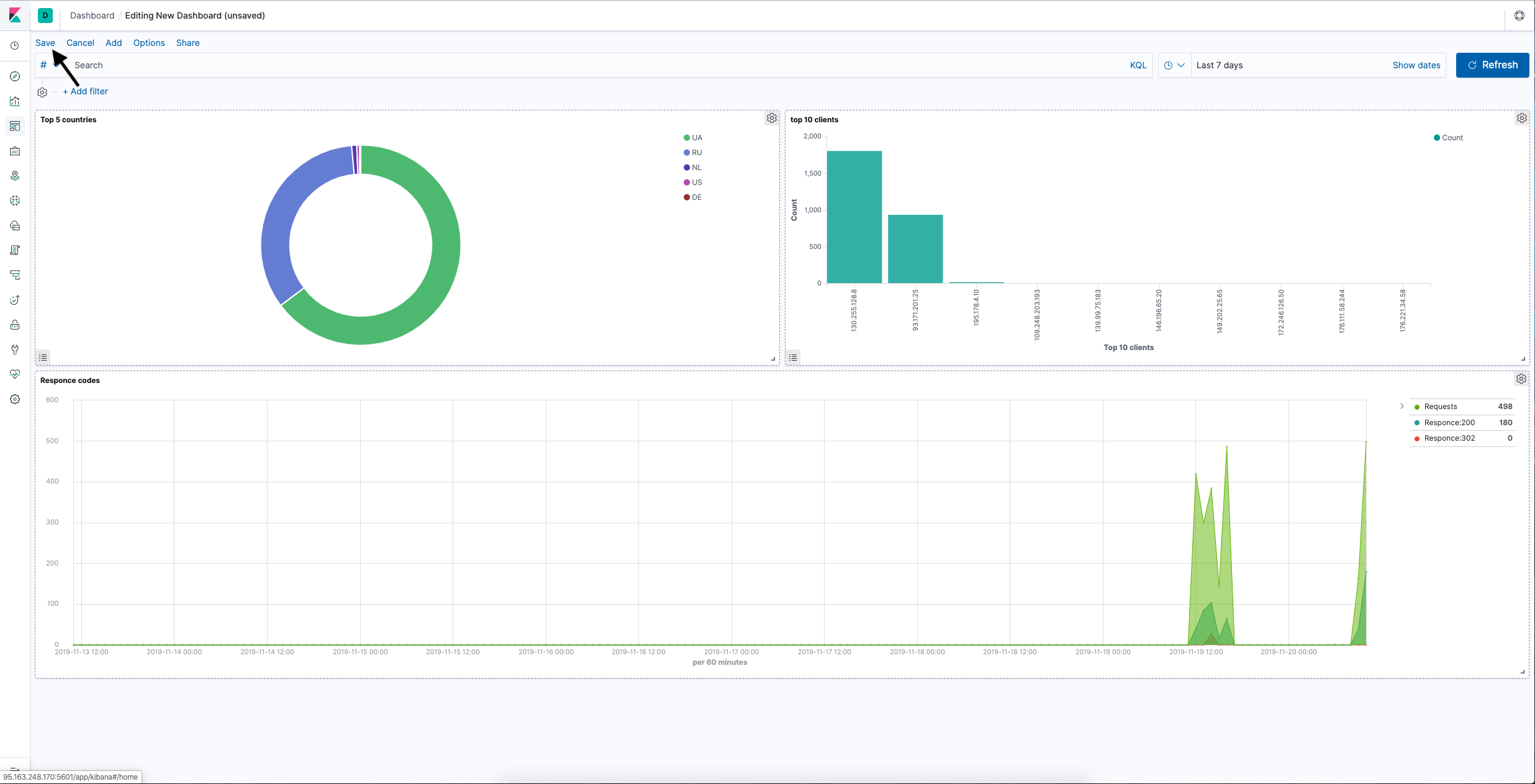
Kibana Dashboard is a set of visualizations.
- Click Dashboards, then Create New Dashboard.
- On the top menu, click Add.

- In the window that opens, select the visualizations you created.
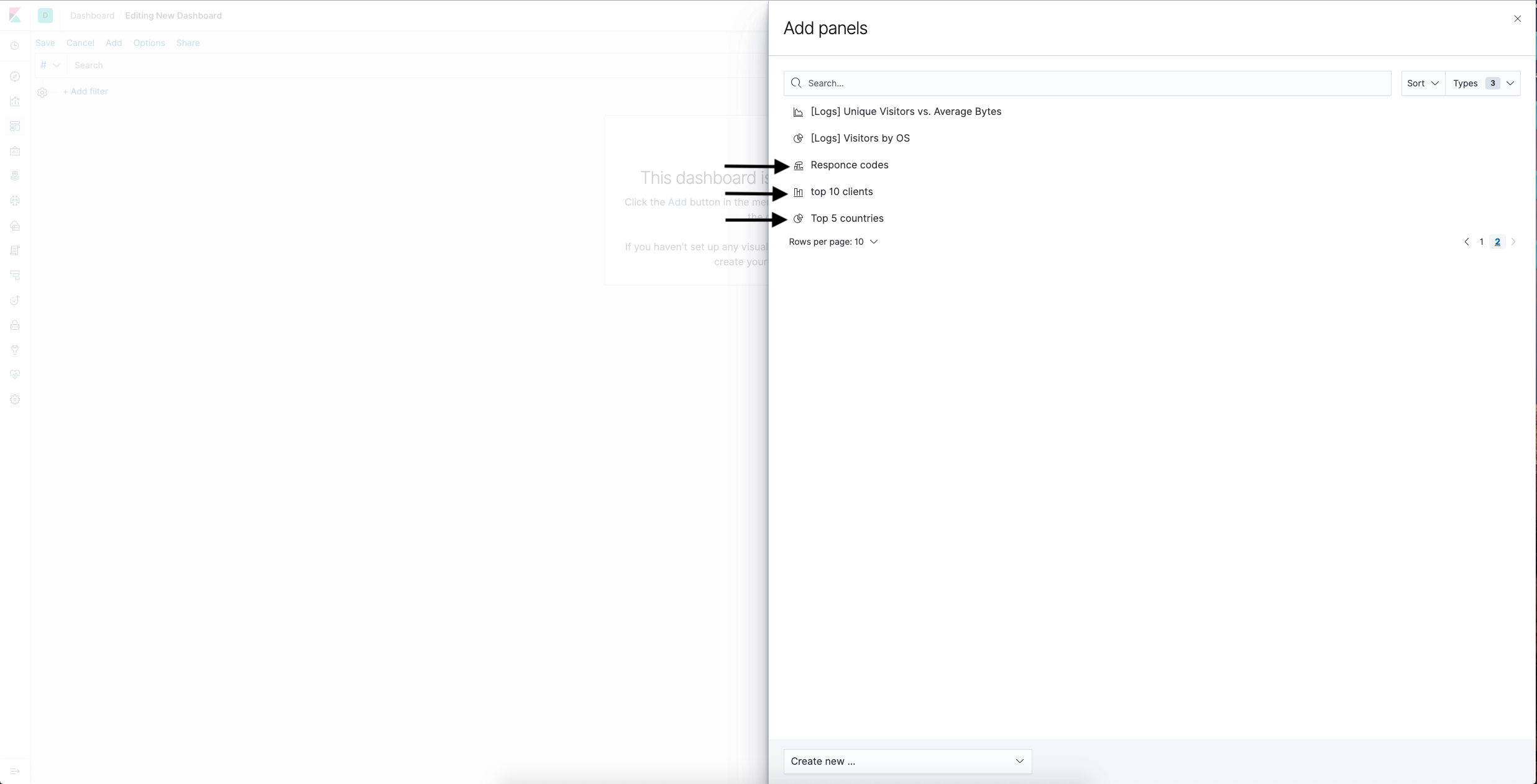
- Reorder and resize the visualizations as needed, then click Save.