How to Set Up Centralized Logging for Docker Swarm with Fluentd
To run this monitoring scenario, install and configure servers using the following hardware:
- Docker on Ubuntu 18.04 LTS x86_64.
- Elasticsearch and Kibana on Ubuntu 18.04 LTS x86_64.

Docker Swarm is Docker in cluster mode. A cluster can consist of one node or several nodes. For this scenario, one node is enough.
Fluentd is a software package responsible for collecting, transforming logs and transferring them for storage. Logstash, a standard component of the ELK stack, has similar functions. However, Fluentd has more options for transferring logs for storage (claimed [more than 40 data outputs] (https://www.fluentd.org/dataoutputs)), as well as higher speed and low resource requirements (when consuming RAM about 40 megabytes processed 13,000 lines per second). Fluentd is currently used and supported by major companies such as Atlassian, Microsoft, and Amazon. Part of the Fluentd project is Fluent-bit, a lightweight log collector/transformer (details read here). In addition, Fluentd, along with projects such as Kubernetes and Prometheus (for details [read here] (https://www.cncf.io/projects/))), is supported by CNCF (Cloud Native Computing Foundation).
To run a script:
- From the ELK stack, we use only Elasticsearch to store the logs that Fluentd will transmit, and Kibana to display them.
- In the Docker Swarm cluster, we will deploy a simple application from several containers, set up the collection of logs from them, as well as the transfer and visualization of logs to ELK. Let's deploy a Wordpress blog as a test application. To directly pass logs to the Fluentd daemon, we use the Fluentd log driver. By default, logs are written to files that can be read by the Fluent-bit daemon, which reduces the chance of logs being lost, since a copy of them is stored in a file. However, using the log driver is more standard practice for Docker Swarm/k8s clusters.
- Login to the Docker node as root.
- Install packages:
root@ubuntu-std1-1:~# apt-get install -y apt-transport-https ca-certificates curl gnupg-agent software-properties-common
- Add the Docker repository key:
root@ubuntu-std1-1:~# curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt key add-OK
- Add the Docker repository:
root@ubuntu-std1-1:~# add-apt-repository \> "deb [arch=amd64] https://download.docker.com/linux/ubuntu\> $(lsb_release -cs) \> stable"
- Install Docker:
root@ubuntu-std1-1:~# apt-get update && apt-get install -y docker-ce docker-ce-cli containerd.io
- Initialize the cluster:
root@ubuntu-std1-1:~# docker swarm init
- Create a directory /root/wordpress and place the following docker-compose.yml file there:
version: '3'networks:frontend:backend:volumes:db_data: {}wordpress_data: {}services:db:image:mysql:5.7volumes:-db_data:/var/lib/mysqlenvironment:MYSQL_RANDOM_ROOT_PASSWORD: '1'MYSQL_DATABASE: wordpressMYSQL_USER: wordpressMYSQL_PASSWORD: wordpressPASSnetworks:- backendlogging:driver: "fluentd"options:fluentd-async-connect: "true"tag: "mysql"wordpress:depends_on:-dbimage:wordpress:latestvolumes:- wordpress_data:/var/www/html/wp-contentenvironment:WORDPRESS_DB_HOST:db:3306WORDPRESS_DB_USER: wordpressWORDPRESS_DB_PASSWORD: wordpressPASSWORDPRESS_DB_NAME: wordpressnetworks:- front end- backendlogging:driver: "fluentd"options:fluentd-async-connect: "true"tag: "wordpress"nginx:depends_on:- wordpress-dbimage:nginx:latestvolumes:- ./nginx.conf:/etc/nginx/nginx.confports:- 80:80networks:- front endlogging:driver: "fluentd"options:fluentd-async-connect: "true"tag: "nginx"
For each container, the Fluentd log driver is described, the background connection to the Fluentd collector is indicated, and additional tags are affixed for further processing (if necessary).
- Place the nginx.conf configuration file in the /root/wordpress directory:
events {}http {client_max_body_size 20m;proxy_cache_path /etc/nginx/cache keys_zone=one:32m max_size=64m;server {server_name_default;listen 80;proxy_cache one;location / {proxy_pass http://wordpress:80;proxy_set_header Host $http_host;proxy_set_header X-Forwarded-Host $http_host;proxy_set_header X-Real-IP $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;proxy_set_header X-Forwarded-Proto $scheme;}}}
- Run containers:
root@ubuntu-std1-1:~# docker stack deploy -c /root/wordpress/docker-compose.yml blogCreating network blog_backendCreating network blog_frontendCreating service blog_wordpressCreating service blog_nginxCreating service blog_db
- Make sure everything started successfully:
root@ubuntu-std1-1:~# docker service lsID . NAME . . . . . MODE . . . REPLICAS .12jo1tmdr8ni 1/1 mysql:5.7rbdwd7oar6nv . . blog_nginx . . . replicated . . 1/1 . . nginx:latest . . \*:80->80/tcpoejvg6xgzcwj . . blog_wordpress . . replicated . . 1/1 . . . wordpress:latest
- In the address bar of the browser, enter the IP address of the server and finish setting up Wordpress:
The result is a system consisting of three containers: a MySQL database, Nginx as a frontend proxy, and an Apache/Modphp container for running the Wordpress codebase. Each container will have its own logs, which we will add for collection and processing.
- Install fluentd:
root@ubuntu-std1-1:~# curl -L https://toolbelt.treasuredata.com/sh/install-ubuntu-bionic-td-agent3.sh | sh
- Add fluentd to startup:
root@ubuntu-std1-1:~# systemctl enable td-agentSynchronizing state of td-agent.service with SysV service script with /lib/systemd/systemd-sysv-install.Executing: /lib/systemd/systemd-sysv-install enable td-agent
The fluentd configuration file is located in the /etc/td-agent/td-agent.conf folder. It consists of several sections, consider them.
Source section - contains a description of the source of the logs. The Docker Fluentd log driver sends logs to tcp://localhost:24224 by default. Let's describe the source section for receiving logs:
<source>@type forwardport 24224</source>
@type forward means the fluentd protocol that runs over a TCP connection and is used by Docker to send logs to the Fluentd daemon.
Data output section in elasticsearch:
<match \*\*>@type elasticsearchhost <IP_ADDRESS_OF_ELK>port 9200logstash_format true</match>
In <IP_ADDRESS_OF_ELK>, specify the DNS name or IP address of the Elasticsearch server.
Such a configuration file is the minimum for sending logs to Elasticsearh, but fluentd's capabilities are not limited to this. It has extensive filtering, parsing and data formatting capabilities.
A typical example of filtering is setting up a selection by regexp:
<filter foo.bar>@type grep<regexp>key messagepattern /cool/</regexp><regexp>key hostnamepattern /^web\d+\.example\.com$/</regexp><exclude>key messagepattern /uncool/</exclude></filter>
This example will select records from the stream that contain the word cool in the message field, the hostname field, for example, www123.example.com, and do not contain the word uncool in the tag field. The following data will be verified:
{"message":"It's cool outside today", "hostname":"web001.example.com"}{"message":"That's not cool", "hostname":"web1337.example.com"}
The following are not:
{"message":"I am cool but you are uncool", "hostname":"db001.example.com"}{"hostname":"web001.example.com"}{"message":"It's cool outside today"}
This example is taken from the fluentd manual. Another good example of using a filter is adding geodata.
Parsers are designed to parse logs of a standard structure (for example, Nginx logs). Parsers are specified in the source section:
<source>@typetailpath /path/to/input/file<parse>@type nginxkeep_time_key true</parse></source>
This is a typical example of parsing Nginx logs. Data formatting is used to change the format or structure of output data and is described in the output section.
The possibilities of fluentd are very wide, their description is beyond the scope of this article. To learn more about fluentd, see the documentation.
When entering Elasticsearch, the logs will be added to the logstash-YYYY-MM-DD index. If you need more complex processing of logs, you can send the logs not directly to Elasticsearch, but to Logstash, and parse and arrange them there.
To view logs:
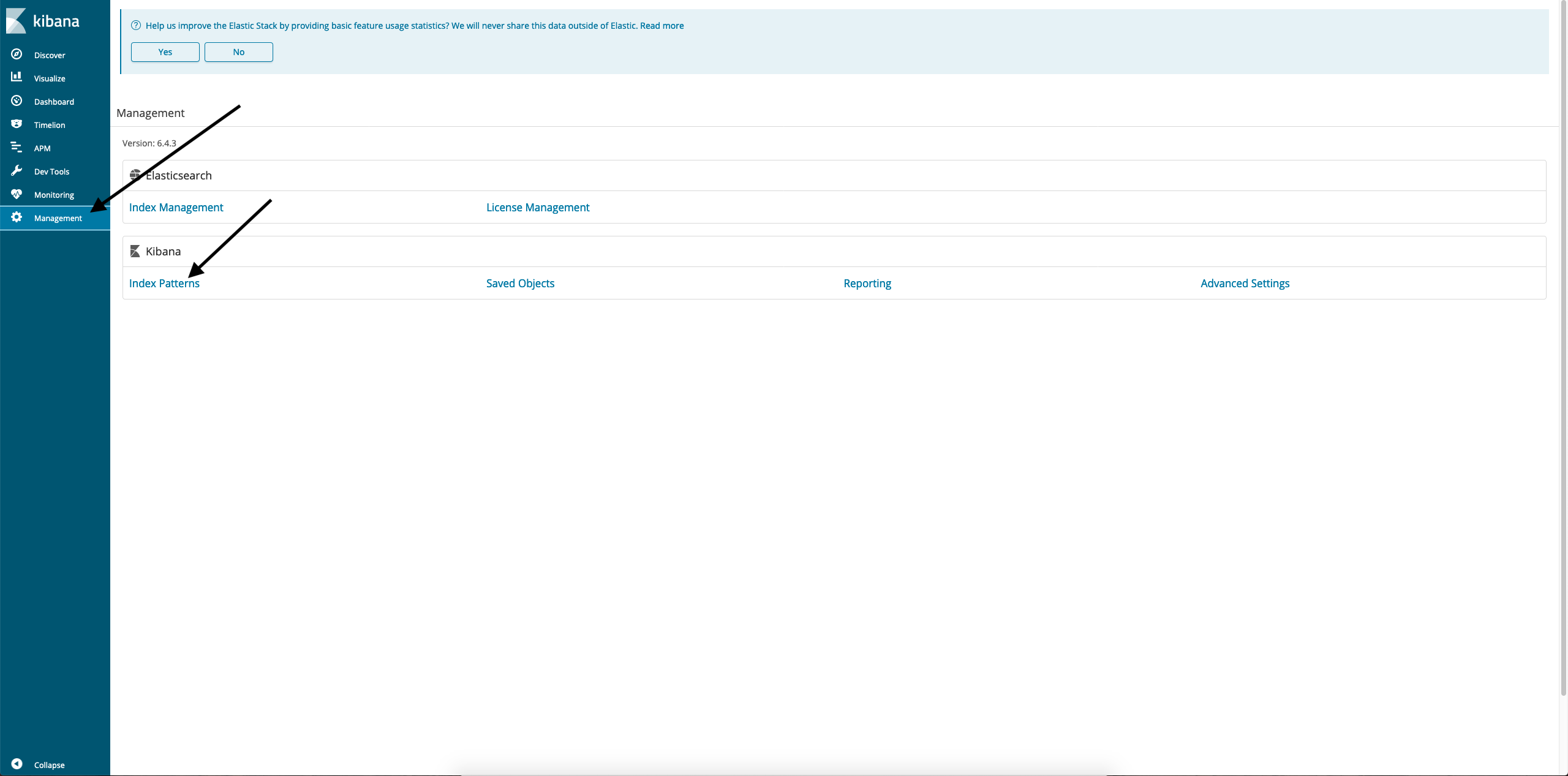
- In a browser, go to the Kibana web console, then click on the Management / Index patterns link.
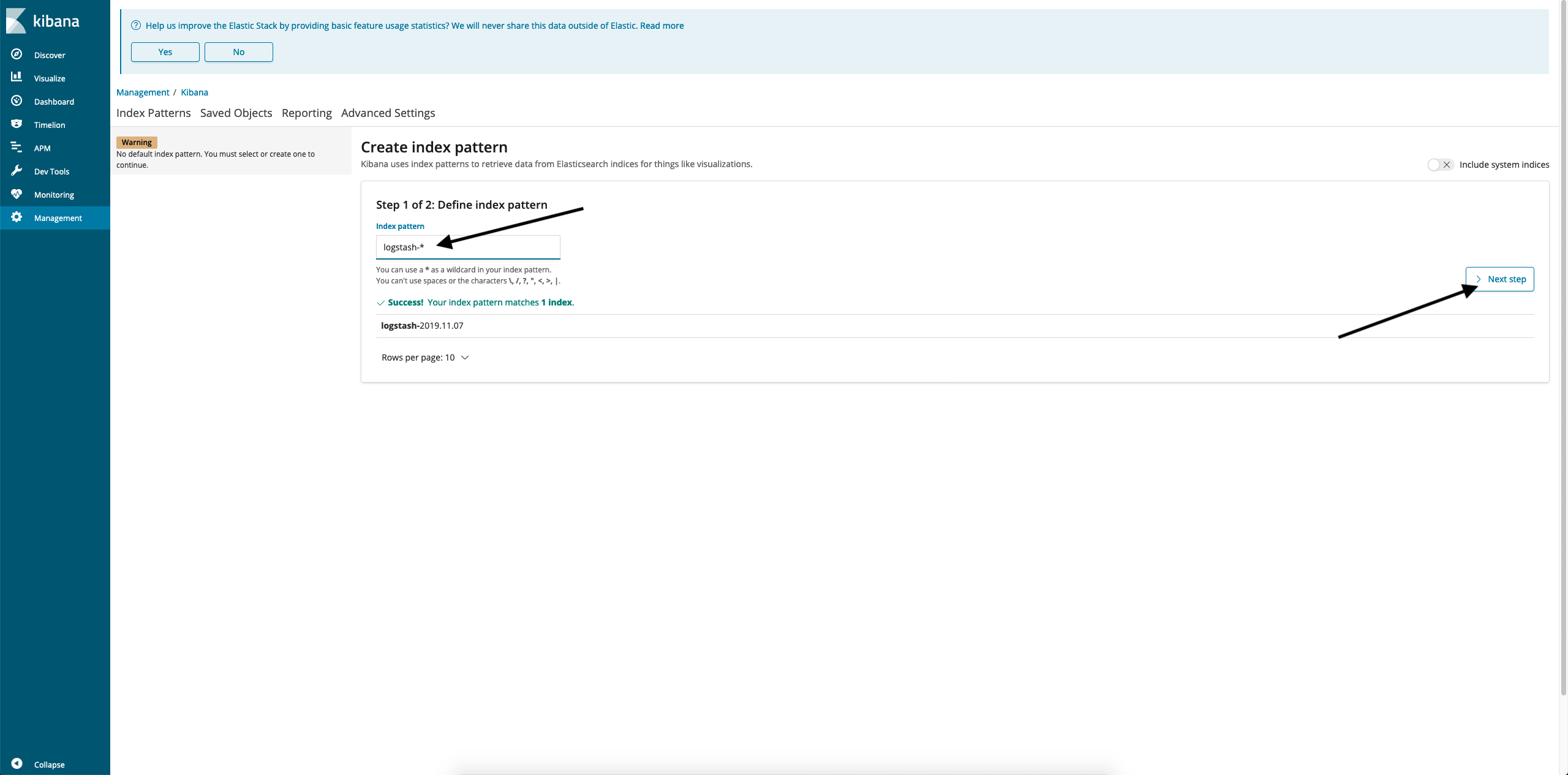
- In the Index Pattern input window, enter logstash-* and click Next Step.
- In the Time filter field name window, select @timestamp and click Create index pattern:
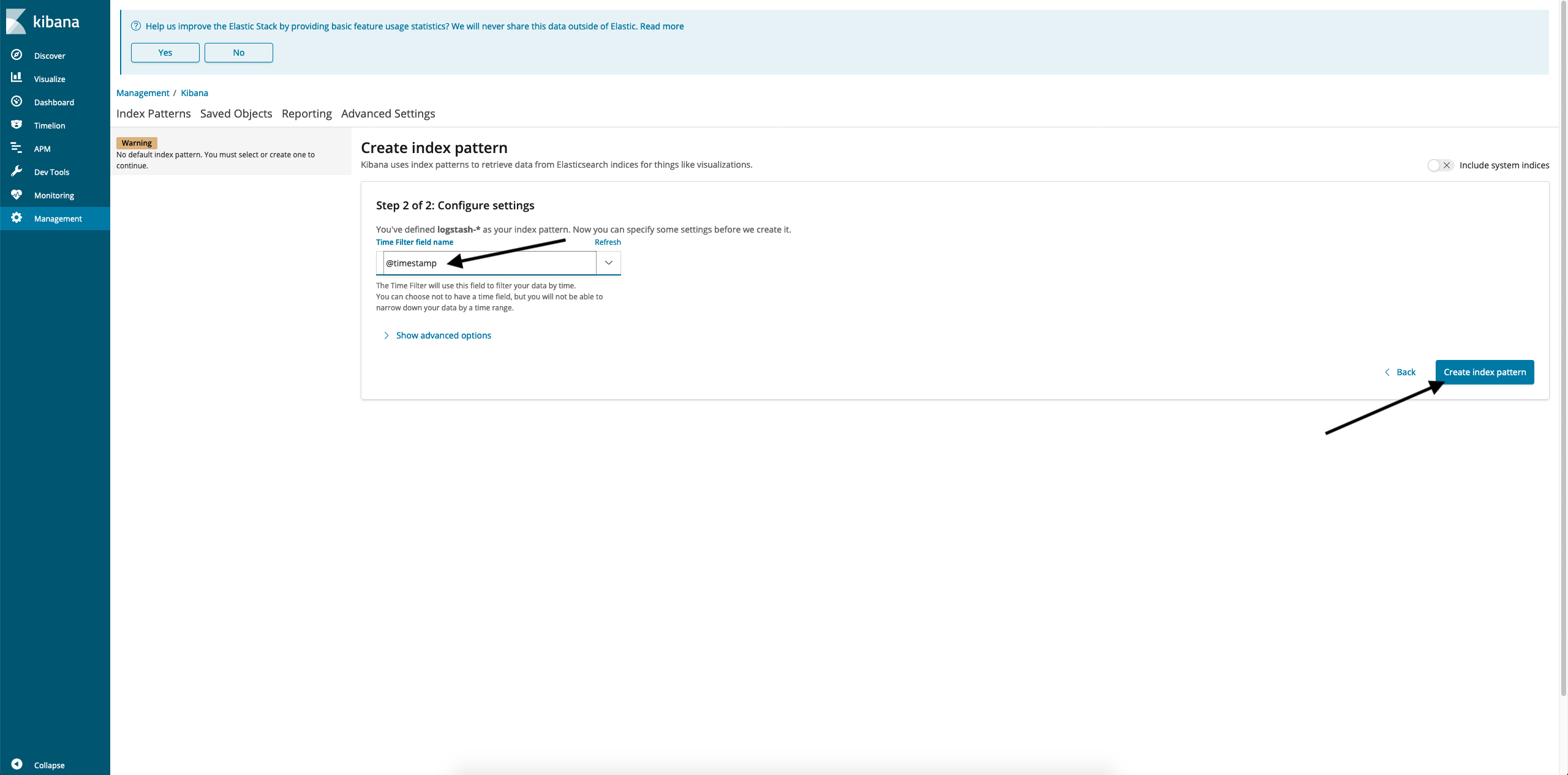
- Index pattern created.
- Go to Discover, select an index. There will be container logs:
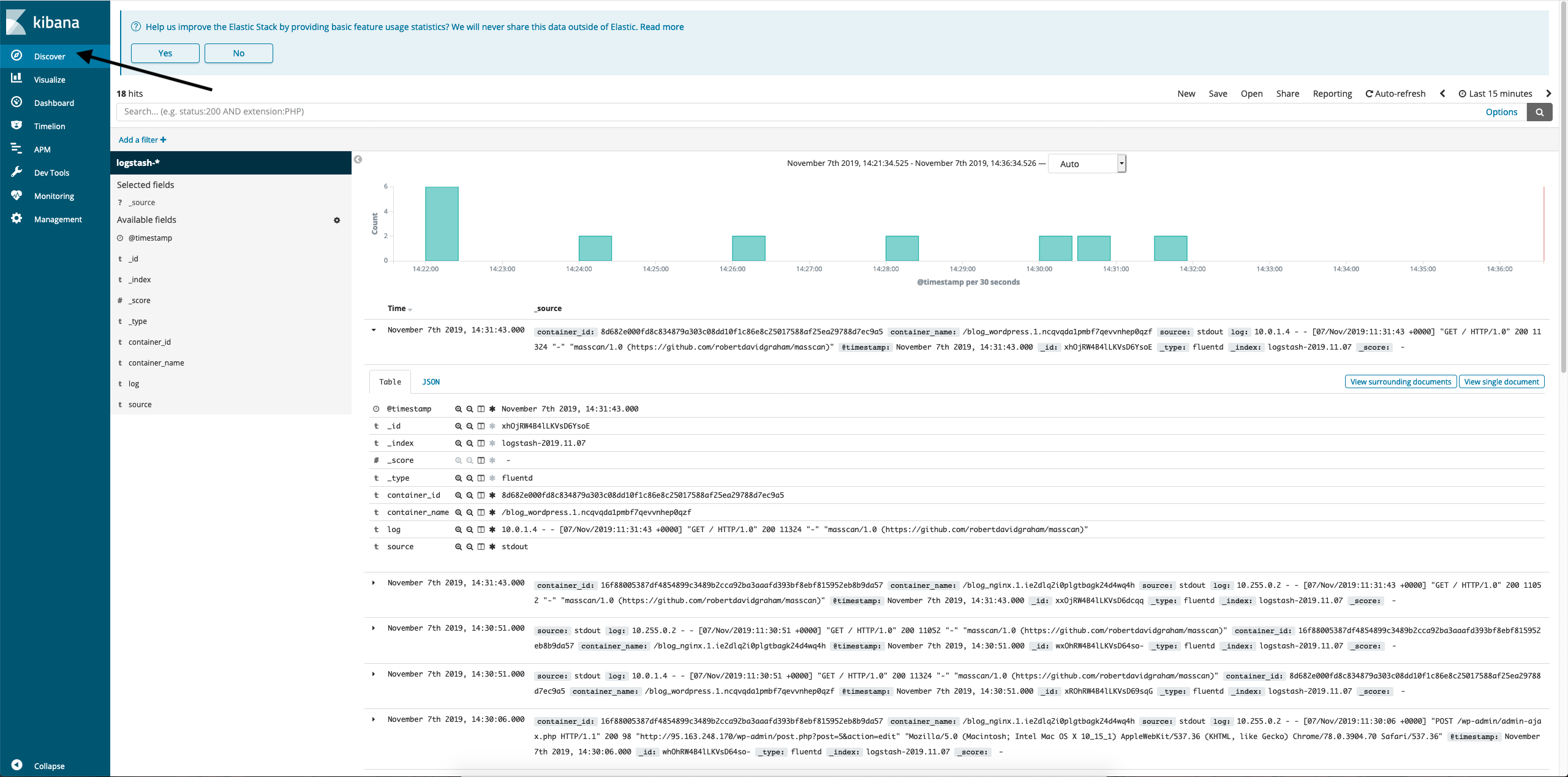
Next, try creating a couple of test posts in Wordpress and look in Kibana for changes in the logs.