
ZFS: архитектура, особенности и отличия от других файловых систем
Я Георгий Меликов, контрибьютор проектов OpenZFS и ZFS on Linux. Также я занимаюсь разработкой IaaS в команде облачной платформы VK Cloud (бывш. MCS).
Хотя в продакшене нашего подразделения мы и не используем ZFS, но хозяева подкаста SDCast пригласили меня рассказать именно о нем. Из выпуска и родилась эта статья, а вот тут можно послушать аудиоверсию.
Итак, сегодня я рассказываю про ZFS. Как устроена файловая система ZFS, из каких компонентов она состоит и как работает, а также про новые фичи, которые появились или скоро появятся в последних релизах.
ZFS и ее отличия от других решений на примере Linux
ZFS — это симбиоз файловой системы и менеджера томов, которая предоставляет инструменты для простого управления дисковым массивом.
Любая файловая система — это абстракция для удобного хранения данных. Каждая файловая система разрабатывалась под определенные требования: сколько у нее будет дисков, какая система хранения под капотом и так далее. Например, семейство EXT — очень простая система, вдохновленная UFS, XFS — система с упором на параллельный доступ, а ZFS стремится быть системой, включающей в себя все нужное для создания больших локальных хранилищ, в частности это отражается и на удобстве эксплуатации.
В Linux как де факто стандарт используется менеджер логических томов (Logical Volume Manager, LVM), который также предлагает некоторые абстракции над нижележащим блочным устройством — можно создавать абстракции в виде Physical Volume, Logical Volume и так далее. По сути, можно делать то же самое, что с ZFS, но другими методами, добавив еще кучу слоев к LVM.
Основы ZFS
ZFS — это copy-on-write файловая система, она никогда не перезаписывает данные. Мы всегда оперируем новым блоком, для обеспечения консистентности данных не нужен журнал, как в большинстве других файловых системах.
У баз данных типа MySQL и PostgreSQL есть так называемый WAL-лог. По умолчанию все данные пишутся в виде лога, потом записываются в блок данных на диске, получается двойная запись. При этом надо ждать, когда файловая система подтвердит, что данные на диске.
Copy-on-write дает следующее преимущество: старые данные не меняются, можно не вести журнал и восстановить данные, записанные ранее. Мы не боимся повреждения данных, так как их нельзя повредить, новый вариант блока запишется в новое место, не затирая старый.
Сам copy-on-write процесс не гарантирует консистентность данных, но если рассматривать ZFS, то в основе его работы лежит дерево Меркла, или Хэш-дерево. У ZFS всегда консистентное состояние за счет того, что он использует атомарные транзакции. Есть дерево блоков, для каждого из них с самого нижнего блока подсчитывается хеш-сумма и так доходит до самого верхнего блока. Хеш-сумма верхнего блока (uberblock) позволяет валидировать состояние всей файловой системы на момент транзакции.

Однако из-за того, что copy-on-write система никогда не пишет в одно и то же место появляется проблема фрагментации данных. Также надо решать вопрос чтения и его эффективности. С SSD эта проблема по большей части решается, но она ощутима при работе на жестких дисках.
ZFS, как и любой copy-on-write системе, нужно иметь на дисках запас свободного места, чтобы было куда записывать данные, которые всегда пишутся в новое место. К этому добавляется проблема порядка записи, следующие блоки одного файла будут записаны в другое место на диске, то есть в наличии непростая задача по эффективному аллоцированию данных. Однако и в классических файловых системах фрагментации можно избежать, только переалоцировав последовательно отрезок и работая только с ним. По факту мы так возвращаемся к прибиванию сущностей программы к конкретному диску, а это менее удобно (а любая ФС, как мы говорили раньше, стремится облегчить жизнь разработчику).
Преимущества ZFS
Давайте же поговорим о плюсах, зачем вообще стоит выбирать ZFS:
Целостность и консистентность — ZFS сделан для максимальной надежности. По умолчанию на все данные подсчитываются контрольные суммы, а для метаданных записывается минимум по две копии в разных местах диска. Есть такой миф, что для ZFS нужна ЕСС-память, на самом деле — она нужна для любой файловой системы для исключения записи некорректных данных, просто в ZFS об этом честно говорят.
Сжатие на лету. К примеру, используя алгоритм сжатия LZ4 система без проблем выдает 800 Мбайт в секунду на одно ядро на запись и до 4.5 Гбайт в секунду — на чтение. Соответственно, если мы говорим про многопоточную нагрузку, то при наличии свободного процессорного времени его можно эффективно утилизировать. В таком случае можно сэкономить не только место на диске, но и IOPS жесткого диска взамен ресурсов процессора за счет меньшего количества операций к диску. Есть интересные кейсы, к примеру использование MySQL, когда при этом под нами не очень дорогой SSD или простой HDD — тогда, включив LZ4, можно хорошо выиграть по многопоточной производительности, немного увеличив latency каждого потока.
Атомарность. В ZFS все атомарно за счет того, что в основе лежит дерево Меркла. Если наша файловая система всегда атомарна, то можно отказаться от WAL-лога в приложениях, потому что целостность блоков гарантируется транзакционностью файловой системы. Тут есть нюансы: нужно уметь говорить с файловой системой на ее языке, манипулировать транзакциями. Отдельный вопрос, что эти логи некоторые базы данных используют для репликации. Но в целом — можно так экономить на ресурсах.
Этот нюанс может быть и минусом: работа через дерево Меркла не бесплатна — чтобы приобрести консистентное состояние, нужно провести все манипуляции по подсчету хеш-сумм. Это дорого в первую очередь относительно процессора. Со стороны доступа к данным — что-то требует больше ресурсов по сравнению с классическими файловыми системами, а что-то меньше, например, мы экономим на том же журнале.
«Бесплатные» снапшоты. Создание снапшота в ZFS по времени константно и не накладывает дополнительных расходов на работу с этими данными. Снапшоты удобно передавать, в том числе инкрементально, Те, кто пользуется бэкапами через Rsync или другие инструменты, сталкиваются с такой проблемой — нужно проверять, какая часть данных изменилась. А здесь можно отправить снапшот инкрементально, целостность будет проверена и подтверждена на другой стороне.
Снапшот, по сути, тег, то есть ссылка на некую версию, всех данных всех блоков, из которых она состоит, начиная от корневого блока. Это специально помеченный самый верхний корневой блок, с которого начинается дерево. За этот счёт получение инкрементального среза изменённых данных равнозначно получению блоков из транзакции, на которую и указывает снапшот, то есть не требуется проверка какие блоки изменились, у нас уже есть ссылка только на модифицированные.
Как пример использования снапшотов можно привести быстрое развертывание разных версий для тестирования дампов баз данных, того же PostgreSQL.
Архитектура ZFS
Посмотрим, как устроена ZFS изнутри. Есть набор дисков, над ним появляется абстракция в виде виртуального устройства (device). В терминологии ZFS — это Vdev, сокращение от virtual device. Есть разные реализации Vdev: Mirror (зеркало), который дублирует как есть информацию на два диска, RAID-Z, похожий по логике работы на классические RAID 5, 6 или 7. Также на подходе новый dRAID, о котором поговорим позже.
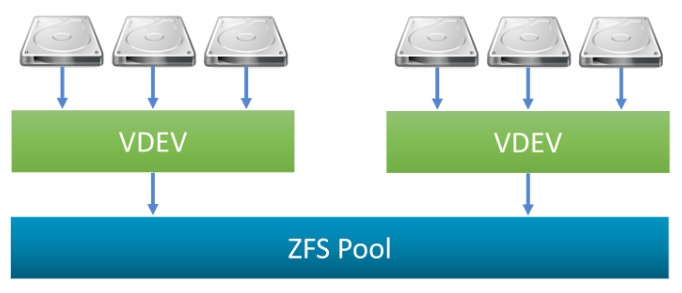
Как конкретно мы храним и резервируем данные — с упором на производительность или на объём полезного пространства — это ответственность Vdev. Из набора Vdev’ов мы составляем общий пул. Если перевернуть на классическое понимание того же mdadm, чтобы собрать RAID 10, то есть набор мирроров, нужно сделать несколько Vdev Mirror и объединить их в один пул. Каждый Vdev — это, по сути, stripe, то есть отдельная виртуальная единица хранения. В рамках пула каждый уникальный блок данных будет храниться только на одном Vdev.
Логически элементы ZFS делятся на 3 подсистемы:
-
SPA (Storage Pool Allocator) — отвечает непосредственно за нарезку на диски, хранение данных на диске. Этот элемент отвечает за то, куда кладется конкретный блок данных, но с абстракцией от диска. Когда мы к нему обращаемся, то видим единое пространство, вне зависимости от набора конкретных Vdev’ов.
-
DMU (Data Management Unit) — на этом уровне ZFS представляется обычным объектным хранилищем. Есть реализации, когда ее так и используют с некоторыми модификациями. К примеру, распределённая файловая система Lustre реализует свой слой поверх DMU ZFS.
-
Следующий уровень DSL (Data and Snapshot Layer) пользуется этим объектным хранилищем. Этот компонент занимается непосредственно файловыми системами, снапшотами, то есть логикой, которая реализует POSIX-совместимую файловую систему (в него входит слой ZPL — ZFS POSIX layer).

Также в ZFS есть другие подсистемы, которые нужны для эффективной совместной работы всех этих слоёв.
ARC (Adaptive Replacement Cache). Его разработали, чтобы решить проблему с чтением. ARC примечателен тем, что делает упор не только на трекинг тех объектов, что были использованы последними (LRU-cache), но и на трекинг частоиспользуемых объектов, которые он и кэширует (MFU-cache).
У классического page cache Linux’а есть проблема вымывания: если прочесть файл, размер которого превышает объем оперативной памяти, то старые данные из кэша вымоются, так как по умолчанию файл будет загружен в page cache.
ARC — это умная замена page cache. Когда создавался ZFS, часто использовали жесткие диски, а у них маленькие IOPS. Чтение copy-on-write данных — по умолчанию случайная операция, чтобы её ускорить, используют разные ухищрения, например, аккумулируют данные, записывают большим блоком и так далее, но эти оптимизации не всегда срабатывают. На этот случай нужно умное кеширование. Нормально, если при штатном работе 99% запросов чтения попадает в кэш, если меньше, значит, что-то не так, стоит добавить оперативной памяти.
Если ARC не всегда полностью помещается в память, есть варианты вынести кэш на более быстрый отдельный SSD — это называется L2ARC (Layer 2 ARC).
ZIL (ZFS intent log). Мы пишем данные в ZFS транзакциями, это набор дорогостоящих операций: подсчет хэш-сумм, построение дерева, запись метаданных, которые пишутся для безопасности несколько раз в разные места дисков. Поэтому мы стараемся набить каждую транзакцию максимальным количеством данных. Тут (сюрприз) появляется определенного вида журнал, без которого не обойтись, если нужна быстрая синхронная запись и критична задержка. Только здесь он вынесен как сущность, что позволяет использовать разные решения для персистентного хранения кусочка синхронной записи. Этот журнал обычно очень маленький, его записью и занимается ZIL (ZFS intent log).
ARC и ZIL — хотя это и необязательные с технической стороны компоненты, но они нужны для обеспечения высокой производительности хранилища, без них система будет работать медленнее. ZFS в продакшене чаще применяют для крупных инсталляций хранилища данных. Архитектура подразумевает эффективную утилизацию большого количества HDD, SSD, RAM, CPU.
Паттерны использования ZFS и типовые конфигурации
ZFS — это локальное хранилище, когда мы говорим про него, то по умолчанию подразумеваем хранилище в рамках одного хоста. У него огромный спектр применения:
-
ZFS подходит для домашнего использования, где не самое дорогое оборудование и не самые быстрые диски, можно использовать процессор на дополнительные вычисления (т.к. он обычно простаивает). Плюсы ZFS в том, что это удобный конструктор. Необязательно задействовать отдельные SSD, можно создать пул даже прямо на файлике, что удобно для тестов.
-
Другой классический вариант — NFS-хранилище, там больше дисков, начинаем задумываться о синхронной записи, кэше и тут можно подставить дополнительные блоки в виде SSD.
-
Также ZFS можно использовать в качестве крупного хранилища, когда в рамках одного пула более ста дисков, все это должно работать и восстанавливаться, если диски вылетели, а это проблема любого большого хранилища.
Блоки типа ARC, ZIL и так далее — это не диски, которые мы можем использовать, это понятия виртуальные, они всегда есть в ZFS. У нас есть возможность вынести их на более быстрые отдельные носители.
ZIL можно вынести на так называемый Slog, которому не нужно быть большим, так как синхронная запись обычно идет мелким блоком и быстро сбрасывается на основное хранилище. То есть важно как можно быстрее записать конкретный блок данных и отрапортовать клиенту об успешной записи, а не записать как можно больше данных (привет, СУБД!). Slog нужен на чтение только при сбое питания.
ARC можно дополнить одним или более SSD и выгружать на него определенный вид данных, например, кэшировать только метаданные или данные, которые последовательно или случайно прочитались с основного хранилища.
Есть много вариаций настройки ZFS. Можно оптимизировать любой профиль нагрузки, начиная от размера блока, которым мы оперируем. Например, когда мы хотим оптимизировать copy-on-write, то можем писать бОльшим блоком, чем в классических файловых системах, для ZFS по умолчанию принят объем в 128 КБайт на блок.
Плюсы и минусы ZFS по сравнению с аппаратными решениями
У аппаратного решения есть плюсы: мы переносим определенную вычислительную нагрузку на его процессор, надеясь, что он с ней справится. Также можно использовать аппаратный RAID-контроллер с энергонезависимой памятью или кэшем, переложить ответственность за проблему с синхронной записью на него.
Минусы аппаратного решения в том, что в случае выхода из строя нужно искать полный аналог. Аппаратный RAID ничего не знает про данные, только про блоки, следовательно, не может как-то оптимизироваться под конкретную ситуацию.
И есть еще момент, который редко упоминается: в случае аппаратных и других софтверных решений — мы настраиваем их единожды, то есть у нас есть общие настройки: один размер блока, такие-то страйпы и так далее. После настройки есть том, с которым можно эффективно работать только с заданными настройками. Отсюда еще один плюс ZFS — возможность настроить один пул под разные нагрузки через создание отдельных датасетов с различными настройками.
Датасет — отдельная файловая система в терминологии ZFS со своими настройками. К примеру, для СУБД можно создать отдельное пространство под основные данные с размером блока 8 Кбайт и отдельный датасет, оптимизированный под WAL-лог с размером блока 16 Кбайт. При этом все будет эффективно работать. Хочется сжимать одни данные — отлично, zfs set compression=on. Другие данные читаются очень редко и могут без надобности вымывать ARC — без проблем, zfs set primarycache=metadata.
Имея один пул, можно настраивать под конкретную операцию хоть каждый датасет. Мы максимально подстраиваемся под приложения. То есть ZFS — очень гибкое софтверное решение.
В случае ZFS все метаданные об ФС пишутся условно в заголовок диска. Если сломался сервер, можно просто вытащить диски и перенести на другой сервер. Если там совместимая версия ZFS, то система их просканирует и снова соберет тот же самый пул.
Любое софтверное решение позволяет так делать, так как рядом с данными хранится информация о строении этого массива. Но ZFS хранит эту информацию на каждом диске — даже не надо указывать порядок, достаточно указать, что где-то есть пул, его надо импортировать. Система либо соберет его, либо покажет, что пошло не так. Также состояние пула можно откатить на несколько транзакций назад, если в них была ошибка.
Особенности работы ZFS
Фрагментация данных
В copy-on-write системе постоянно появляются новые блоки, а старые не всегда пригодны к удалению. Часто возникают ситуации, когда старый блок не полностью записан, какие-то блоки не нужны, появились «дырки» (пустые пространства небольшого размера) и так далее.
В рамках этих пространств мы при каждом аллоцировании пытаемся найти наиболее подходящее по определенному алгоритму. Когда в пуле много места, то выбираем пространство с самым большим объемом свободного места, куда будет лучше записать данные с точки зрения дальнейшей фрагментации. Например, если у нас 1 Мбайт данных, мы ищем свободный блок в 1 Мбайт и можем туда цельно записать данные.
Когда места становится мало, включается другой режим аллокации — он дороже с точки зрения производительности и приводит к росту фрагментации, в этом режиме просто ищется первое попавшееся подходящее место. В худшем случае, когда под блок уже нет безразрывного отрезка, он будет разбит и записан кусками (что тоже не идёт на пользу производительности).
По умолчанию на каждый Vdev создается ~200 meta-slabs. Если что-то изменилось, то надо метаданные по этим 200 meta-slabs записывать каждый раз для каждого Vdev. Сейчас это пишется постоянно на каждый Vdev, но уже перед релизом патч, который записывает информацию об изменениях в meta-slabs в виде лога на один из Vdev, а потом регулярно применяет этот лог. Это чем-то похоже на WAL-лог базы данных. Соответственно, уменьшается нагрузка на запись на диск информации о metaslabs.
Конечно, при заполнении всего места возникает проблема, но на эту ситуацию любая copy-on-write файловая система (да и традиционная тоже) закладывает какой-то процент зарезервированного места для работы, без этого с динамической аллокацией никак.
Запись данных
По умолчанию чтение данных в ZFS практически всегда является случайным, но так как мы пишем каждый раз в новое место, то можем превращать случайную запись в практически последовательную. Если нужна система хранения под запись и редкое чтение, то любая copy-on-write система, в том числе ZFS, будет отличным решением. Данные пишутся группами транзакций (txg, сокращённое от transaction groups), можно агрегировать информацию в рамках этой группы.
Тут есть особенность: существует Write Throttling — мы можем использовать неограниченное количество оперативной памяти для подготовки txg-группы и за счет этого переживать резкие скачки записи, буферизируя все в оперативную память. Естественно, речь про асинхронную запись, когда мы можем себе это позволить. Потом можно последовательно и очень эффективно сложить данные на диск.
Если синхронная запись и ее целостность не важна, например, у вас не большая и дорогостоящая PostgreSQL, а сервер на одного пользователя, то синхронную запись можно отключить одной настройкой, она станет равняться асинхронной (zfs set sync=disabled).
Таким образом, собрав пул из HDD, можно ими пользоваться как дешёвыми SSD с точки зрения IOPS. Сколько IOPS даст оперативная память, столько и будет. При этом целостность ZFS обеспечивает в любом случае — при потере питания произойдет откат на последнюю целую транзакцию и все будет хорошо. В худшем случае мы теряем последние несколько секунд записи, сколько у нас настроено в параметре txg_timeout, по умолчанию — это до 5 секунд, (до — т.к. ещё есть задаваемый лимит на размер буфера, при превышении данные запишутся раньше).
Зависимость скорости работы ZFS от количества дисков
Один блок данных всегда приходит на один Vdev. Если мы делим файл на небольшие блоки по 128 KB каждый, то такой блок будет на одном Vdev. Далее мы резервируем данные с помощью Mirror или как-то еще. Набив пул сотней Vdev, мы в один поток будем писать только на один из них.
Если дать многопоточную нагрузку, например в 1 000 клиентов, то они могут использовать сразу много Vdev параллельно, нагрузка распределится. При добавлении дисков мы, конечно, не получим полностью линейного роста, но параллельная нагрузка эффективно размажется по Vdev’ам.
Обработка запросов на запись
Когда много Vdev и идут запросы на запись, то они распределяются, есть диспетчеризация и приоритезация запросов. Можно посмотреть, на какой Vdev идет нагрузка, каким блоком данных, с какой задержкой. Есть команда zpool iostat, у неё куча ключей для просмотра различной статистики.
ZFS учитывает, какой Vdev был перегружен, где нагрузка меньше, где какая была задержка доступа к носителям. Если какой-то диск начинает умирать, у него высокая задержка, то система в итоге отреагирует на это, например выводом его из использования. Если мы используем Mirror, то ZFS пытается распределять нагрузку и параллельно считывать с обоих Vdev разные блоки.
Как появились OpenZFS и ZFS on Linux и проблемы с версионированием
ZFS изначально создана в Sun Microsystems для проприетарной операционной системы Solaris. Она появилась в качестве замены UFS, которая должна была покрыть любые надобности от файловой системы на долгое время (характерно само название ZFS — Zettabyte File System, намёк на недостижимые объёмы). После продукт стал распространяться с открытым кодом под лицензией CDDL и названием OpenSolaris.
Затем Oracle купили Sun Microsystems, и проект перевели обратно в разряд проприетарных. До этого FreeBSD успел притянуть к себе код, были наработки у Apple, они даже встроили реализацию в штатную поставку, но отказались от нее, в конечном итоге внедрив свой аналог AFS. Тогда же появился форк, который превратился в OpenZFS. Сначала желающие работали на OpenSolaris, а потом создали OpenZFS, под которым собрали все усилия в рамках Illumos (форк OpenSolaris).
У ZFS on Linux другая история. В Ливерморской национальной лаборатории США в качестве распределённой файловой системы для суперкомпьютеров использовали Lustre FS. Ее особенность в том, что на каждой ноде под ней используется еще одна локальная файловая система Ldiskfs — это патченный Ext3, наработки которой послужили основой для Ext4. У Ldiskfs был ряд недостатков, и ZFS должен был заменить эту файловую систему, так и появился проект ZFS on Linux.
В OpenZFS возникла проблема версионирования. Есть ZFS от Oracle и есть OpenZFS, последний не может повторять проприетарную версию, как и банально получать ее исходный код. Изначально и у пула и у датасета в ZFS была версия, при обновлении Solaris можно было просто поднимать соответствующую версию. После обновления пул может не импортироваться в старом коде вообще или импортироваться в режиме только для чтения.
На тот момент в проекте OpenZFS уже было много реализаций: FreeBSD, Linux, Solaris, Macos, нужно было связать все наработки. Для этого придумали feature flags, т. н. функциональные флаги. Например, взводишь флажок, что пул поддерживает LZ4 сжатие и в дальнейшем смотришь на него из кода — поддерживается/не поддерживается фича (т. е. можно ли импортировать пул).
У каждого флага есть подпись — можно ли импортировать пул с ним в режиме только на чтение, так как многие вещи важны только при изменениях данных на носителях. Каждая реализация стала обрастать своими feature flags, и платформы переносили их между друг другом через backports.
ZFS не включен в ядро Linux, а другие файловые системы в Linux идут из коробки, т.е. есть в ядре. Вопрос включения в ядро — проблема лицензии, это вопрос сложный. Однако есть отдельный модуль ядра, его можно без проблем обновлять вне зависимости от версии ядра.
В Linux для этого есть два механизма:
-
DKMS — динамическая сборка из исходников. К новому ядру автоматически ставим headers, которые нужны для сборки модуля, он приезжает и автоматически собирается с нужными параметрами. В худшем случае, если не проверена совместимость, DKMS ничего не соберет и отрапортует об этом, но риск такого очень мал, к тому же сопровождающие репозитории пакетов конкретных дистрибутивов могут проверять совместимость пакетов с доступными версиями ядра.
-
KMOD — модуль ядра приезжает из репозитория в бинарном виде, конкретная сборка совместима с определённой версией ABI ядра. Отсутствует риск проблем при сборке модуля, характерные для DKMS, но сопровождающие пакета с модулем должны оперативно предоставлять новые версии при появлении свежих ядер.
Разница в том, что приедет из пакета: исходный код как в DKMS или сразу бинарный файл как в KMOD.
Что нового в последних релизах
В версии 0.8 появилось нативное шифрование. Есть американская компания Datto, которая занимается бэкапами данных и базируется на ZFS. Они предложили реализацию нативного шифрования.
Ее плюс в том, что шифруются только данные и то, что связано с ними, а информация о датасетах и большая часть метаданных не шифруются. То есть информация на уровне DSL, о директориях и так далее, шифруется, а то, что ниже — DMU и SPA, нет. Что это дает? Можно зашифровать данные на стороне клиента и, не отдавая ключ, отправить их сначала полностью, потом регулярно обновлять инкрементально, принять на стороне сервера также инкрементально без расшифровки и проверить целостность.
Если шифрование идет на низком уровне (к примеру, LUKS) и у нас большие объемы данных, то теряется информация о том, что там есть, нужно передавать все целиком, так как изменение одного байта меняет весь блок. Чтобы проверить целостность данных в этом случае, нужно их расшифровать — это дорого и долго.
Еще одно обновление — это Special Allocation Class. Предположим, что есть большое количество медленных жестких дисков плюс используется реализация Vdev RAIDZ, особенность которого в том, что он не заточен на большие IOPS. Так обеспечивается целостность, он всегда атомарен (не страшна проблема потери массива при т. н. raid write hole), но у этого есть минусы в части производительности. Читать метаданные и мелкие блоки с RAIDZ дорого.
Планы по развитию ZFS
ZFS — файловая система, которая может работать с большинством операционных систем. Скоро появится полнофункциональная версия даже под MS Windows.
Другие направления — больше удобства для конечных пользователей-частных лиц. При использовании ZFS дома есть проблема в том, что объем наращивается либо установкой нового Vdev, либо заменой всех дисков в Vdev на бОльшие (ZFS видит, что диски увеличились и может использовать дополнительное пространство). То есть собрав один RAIDZ, мы не можем добавить к нему на ходу еще один диск. Уже в альфе патч, который позволяет это делать.
Еще одна интересная наработка, которая готовится к релизу, это новый тип Vdev — dRAID. В больших инсталляциях, где диски измеряются сотнями, а пространство — петабайтами, при вылете одного диска сложно быстро восстановить избыточность данных.
Проблема в том, что жесткие диски, наращивая объем в 20 ТБ и более, не сильно наращивают производительность с точки зрения пропускной способности. У любого диска есть количество ошибок на каждый терабайт чтения, официально заявленное производителем (URE — unrecoverable read error rate). И любой RAID 5 и более с дисками больше 3 ТБ практически гарантированно развалится при пересборке, когда один диск вылетел и мы читаем с оставшихся. Риск ошибки чтения хотя бы одного не того байта с этих 3 ТБ каждого диска просто огромен (для «потребительских» HDD стандартом является одна ошибка чтения на каждые 10^14 бит, т.е. на каждые ~11ТиБ). Когда мы пересобираем RAIDZ, а это тот же RAID 5, 6 и так далее, есть та же проблема.
Конечно, можно увеличить количество дисков, которое мы можем потерять: поставить RAIDZ 2, RAIDZ 3 — сколько копий будет хранится, но мы не решаем вопрос производительности восстановления. Новый диск, который мы меняем, по-прежнему является узким горлышком. Эти 15-20 ТБ будут восстанавливаться в лучшем случае со скоростью 200 МБ/сек (а в реалистичном — около 100 МБ/сек, а то и меньше). Несколько суток на восстановление одного диска — это очень долго.

dRAID решает проблему одновременного восстановления данных на большом количестве дисков. Вместо того чтобы работать в рамках «один диск — одна единица», мы как бы нарезаем каждый диск на мелкие сущности по количеству дисков. Так, если в dRAID 50 дисков, то каждый из них будет разделен на ~50 областей. Некоторые из этих областей будут зарезервированы как свободные (spare) области, на которые можно восстановиться.

По сути, это RAID 5 или RAIDZ, повернутый на 90 градусов. Мы в рамках физических дисков имеем виртуальные сущности. Если вылетает один диск, то на других зарезервировано свободное место, можно восстановить вылетевший диск со скоростью, которая зависит от количества элементов в массиве. То есть когда у нас десять блоков данных, можно восстанавливаться сразу на десять дисков. Такой подход увеличивает скорость восстановления.
Например, мы собрали dRAID, аналогичный RAIDZ2 с одним spare диском, который позволяет вылететь двум дискам, один вылетел, осталось девять. Пока мы не вставили новый диск, размазываем данные на пустое зарезервированное пространство других дисков в группе. И так восстанавливаем ситуацию: дисков по-прежнему девять, но вылететь может уже два, а не один, ведь блоки с вылетевшего диска уже разъехались по уцелевшим оставшимся. Таким образом снимается проблема узкого горлышка в виде производительности spare диска, технически он теперь размазан на другие диски массива.
По этой же причине теперь можно задействовать spare диск, в RAIDZ он бы стоят без дела, а в dRAID он является активным участником, т.к. размазан по всем дискам.
Послесловие
В связи с тем, что ZFS пережил существование в разных компаниях и ОС, идёт активная централизация кода и документаций в проекте OpenZFS. Приглашаю желающих к созданию единой документации по проекту, буду рад вашим PR!
Полезные ссылки:
- Проект openzfs на github
- Общая документация
- Newcomer Resources
- Developer resources
- Неофициальный telegram-чат сообщества OpenZFS на русском
Также, как я уже говорил, в основном блочном и объектном хранилище VK Cloud (бывш. MCS), которое разрабатывают коллеги в моей команде, хранение устроено по-другому, об объектном хранилище недавно подробно рассказал наш архитектор Монс Андерсон: Архитектура S3. 3 года эволюции VK Cloud Storage.
P.S. Наш проект ищет разработчиков на Go в команду Identity Access Management. Из интересного — разработка на open source, highload, Kubernetes, распределенные системы. А полный список наших вакансий — здесь.





