
























«Ашан»: как мы построили платформу для аналитики сотен Тб данных и ML в публичном облаке


- Компания
«Ашан Ритейл Россия»
- Отрасль
Ритейл
- Магазины
260 магазинов
- Объем данных
120 терабайт



«Ашан» — один из крупнейших российских ритейлеров. В компании разработали алгоритмы машинного обучения, промышленное внедрение которых помогло бы ритейлеру точно планировать закупки, сокращать издержки и значительно увеличить продажи.
Осталось только построить гибкую и эластичную инфраструктуру для разработки ML-моделей, построения прогнозов и аналитики данных. Лучшим решением было разместить единую Big Data-платформу в облаке, а для этого понадобилось выбрать надежного технологического партнера, способного быстро отвечать на рост потребностей ритейлера.
Как «Ашан» нашел своего провайдера и построил платформу для работы с данными и ИИ в публичном облаке, а также как это улучшило бизнес-процессы компании, рассказал Александр Дорофеев, руководитель группы Big Data компании «Ашан Ритейл Россия».
«Ашан» — один из крупнейших российских ритейлеров
«Ашан Ритейл Россия» — российское подразделение Auchan Retail (входит в Auchan Holding). «Ашан Ритейл Россия» — крупная торговая сеть, работающая на российском рынке с 2002 года. На сегодняшний день открыто 260 магазинов трех форматов: гипермаркеты, суперсторы и супермаркеты. В компании работает 35 000 человек.
Как мы пришли к тому, чтобы использовать искусственный интеллект в облаке
Ритейл становится все технологичнее, ритейлерам важно быстро принимать точные решения, чтобы быть конкурентоспособными. Поэтому одним из глобальных трендов стало внедрение прогнозных и рекомендательных систем на основе Machine Learning.
Наше подразделение Big Data занимается целым рядом задач, которые напрямую влияют на ключевые показатели эффективности бизнеса: это решения в области прогнозирования спроса на различные товары и определения оптимальной цены (так называемая эластичность спроса), сегментации клиентов, повышения лояльности и другие.
В рамках стратегии цифровой трансформации компании команда Big Data и бизнес-эксперты разработали алгоритмы машинного обучения. Их промышленное внедрение помогло бы нам повысить как долю рынка, так и эффективность бизнеса.
Одним из основных препятствий, мешающих развернуть AI-решения, было отсутствие современной инфраструктуры и технологий для работы с большими данными. Наиболее яркий пример — наш алгоритм прогнозирования спроса, который позволяет планировать закупки, сокращать издержки и количество нереализованных остатков на складах. Да, он дает точность прогноза на 20-25% выше, чем существовавшие до этого алгоритмы, но используемые на тот момент базы данных и системы не могли работать с технологиями Big Data (Python, Spark).
Поэтому все обучение шло на рабочих компьютерах Data Scientists. Для витрин данных использовали On-premise базу данных Oracle Exadata, которая также служила OLTP-базой для обеспечения работы бизнеса. Мощности рабочих станций хватило для пилотного проекта, но было понятно, что для промышленной эксплуатации нужны другие ресурсы: нельзя было масштабироваться, в частности, из-за невозможности параллельной обработки данных, кроме того, работу нужно было автоматизировать, а не делать все вручную.
Также аналитические проекты на Oracle Exadata влияли на производительность базы и стабильность основных процессов. Это не устраивало нас и бизнес, в том числе поэтому надо было вынести задачи, связанные с аналитикой, в отдельный контур.
Решить все эти проблемы могла бы единая Big Data-платформа для тестирования и тренировки моделей машинного обучения, ad hoc-отчетов и исследований, которая позволила бы:
- собирать, хранить и обрабатывать большие объемы данных;
- обеспечить разработку и внедрение в продуктивную эксплуатацию AI-решений;
- поддерживать лаборатории данных для различных продуктовых и функциональных команд.
Сначала мы решили определиться с тем, какие технологии нужны, чтобы Big Data Platform соответствовала всем вышеуказанным целям. Для этого мы составили список AI-продуктов, которые нужны нашей компании в ближайшие два года.
Также мы решили, что архитектура платформы должна отвечать следующим требованиям:
- используются только Open-Source-технологии;
- все компоненты должны быть масштабируемыми;
- есть поддержка микросервисной архитектуры;
- соответствие корпоративным требованиям и требованиям законодательства РФ в области работы с данными.
Для каждого AI-продукта мы выбрали технологии реализации и сделали предварительную оценку требуемых ресурсов: диски, RAM, CPU, сеть. В список технологий вошли современные инструменты для работы с ML: Hadoop, Spark, Kubernetes и другие. После этого мы стали определяться с тем, где разместить платформу: на своих мощностях или в облаке.
Облако или On-premise: что лучше подходит для реализации Big Data-платформы с нужной функциональностью
У каждого варианта есть свои плюсы и минусы, самый волнующий для всех — это затраты. Мы посчитали, что затраты на построение платформы в облаке в первые два года будут существенно ниже, чем при ее развертывании на собственных мощностях, что благотворно скажется на ROI от инвестиций в инфраструктуру Big Data.
При этом, по нашим оценкам, на горизонте пяти лет затраты на развертывание и поддержку платформы накопительным итогом равны между собой.
Также облачную инфраструктуру легко масштабировать — можно быстро получить нужные ресурсы для поддержки наших ML-решений. Еще в облаке доступны многие необходимые нам технологии в готовом виде — как aaS.
Мы поняли, что для построения единой облачной платформы для ML-экспериментов, Data Science и аналитики необходим надежный провайдер, который соответствовал бы нашим требованиям и предлагал все нужные технологии.
Почему выбрали VK Cloud: успешный пилот и соответствие всем требованиям
При выборе облачных провайдеров для пилотного проекта ориентировались на несколько параметров.
- Наличие зрелых платформенных технологий:
- Hadoop для хранения и обработки холодных данных;
- Spark;
- Kubernetes;
- ClickHouse для работы с горячими данными;
- MPP-системы — в качестве нее мы рассматривали Greenplum, ему нет альтернатив среди Open Source. Мы решили использовать сервисы на основе Open Source-технологий, уйти от вендорских решений, так как Open Source дает гибкость архитектуры, а также с ним больше опыта работы на рынке.
- Соответствие требованиям нашей службы безопасности, наличие нужных аттестатов и сертификатов, соответствие 152-ФЗ для хранения чувствительных данных, закрытый контур внутри публичного облака.
- Соотношение цены и качества предоставляемых услуг.
Также смотрели на успешность пилота, который был сложным: нужно было уложиться в определенный временной интервал, создать определенное число моделей, загрузить их, чтобы они были доступны, развернуть инфраструктуру, показать, что она работает.
Облачная платформа VK Cloud соответствовала всем требованиям, а еще здесь хорошая техподдержка, которая помогала оперативно решать все вопросы, поэтому выбор остановили на этой платформе.
Миграция и развертывание компонентов платформы прошли без проблем. Исторические данные на новую Big Data-платформу наши дата-инженеры переносили самостоятельно, у них большие компетенции в работе с Hadoop. Использовали такие инструменты, как Talend и Apache Sqoop, который входит в состав сборки Hadoop от VK Cloud. Sqoop предназначен для транспортировки в Hadoop данных из классических реляционных баз, таких как Oracle, MySQL и PostgreSQL. Также настраивали Check Point для организации VPN.
Какие облачные сервисы будут использованы для реализации Big Data-платформы
Для реализации Big Data-платформы используем следующие облачные сервисы:
- Cloud Big Data на основе Hadoop и Spark — хранилище сырых и холодных данных — сюда из источников выгружают данные, на которых тренируют модели и строят отчеты.
- СУБД ClickHouse в облаке — здесь размещаются продуктовые витрины для наших AI-решений и витрины для аналитиков, можно подключать BI-инструменты.
- СУБД Arenadata DB Cloud на основе Greenplum — это аналитическая база данных, где можно работать с SQL, делать ad hoc-запросы и строить комплексные витрины, что не очень удобно делать в ClickHouse.
- Kubernetes как сервис — обучение ML-моделей требует большого количества ресурсов, с помощью автомасштабирования Kubernetes позволяет получать их тогда, когда они нужны, а потом возвращать в облако.
Архитектура Big Data-платформы в облаке VK Cloud
Мы использовали лучшие практики для реализации архитектуры Big Data-платформы. На текущий момент на платформе не только ведется разработка AI-продуктов, но и уже развернуты два решения искусственного интеллекта и лаборатории данных.
С учетом небольших корректировок по итогам шести месяцев работы Auchan Big Data Platform выглядит так:
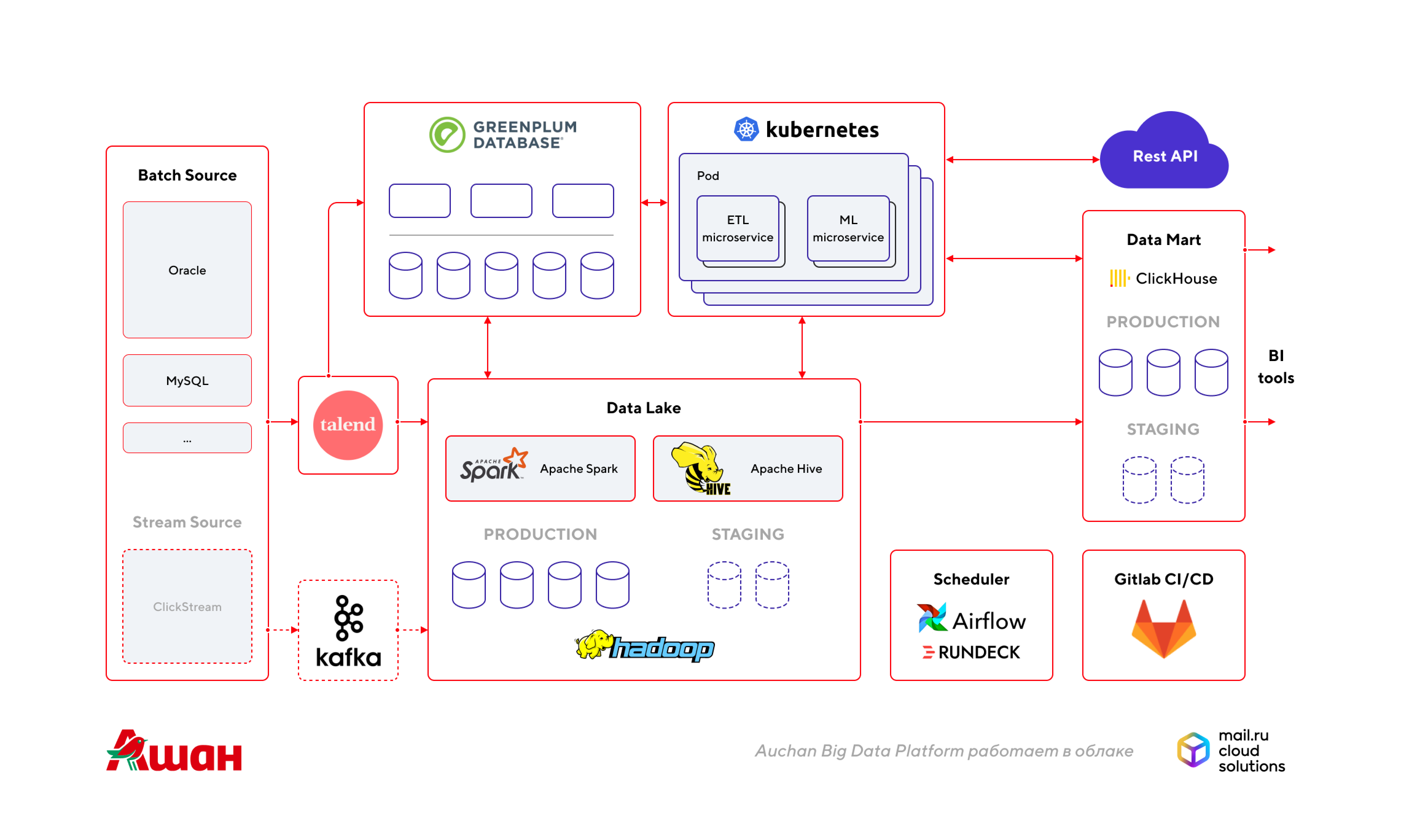
Здесь есть внутренние и внешние источники, из которых мы загружаем данные в Hadoop. Для загрузки данных из источников используем Sqoop, Talend, а также Kafka для загрузки данных в режиме реального времени или близком к нему.
Далее обрабатываем данные с помощью Spark (он работает на тех же виртуальных машинах), строим витрины данных для аналитиков. Витрины данных и детальные данные, которые часто используются, передаются в ClickHouse, которая может быстро отдавать результаты.
Пока Spark работает поверх Hadoop, но с ростом числа ML-моделей планируем поднять отдельный кластер Spark, где будут развернуты алгоритмы, и запускать его из Kubernetes. В Hadoop загружаем исторические данные с глубиной в несколько лет, причем только те, что необходимы для наших ML-решений. Общий объем данных уже превысил 120 Тб, то есть через платформу проходит большой объем данных.
Далее планируем для ad hoc-запросов и построения тяжелых витрин, объединяющих несколько источников, передавать данные в Arenadata DB Cloud. Эта СУБД на основе Greenplum позволяет объединять большие объемы разных данных и строить массивные таблицы: например, миллиард строк продаж объединить с миллионами клиентов — получаются десятки миллиардов строк пересечений. В Hadoop это делать долго, в ClickHouse почти невозможно.
Arenadata DB Cloud позволит организовать лабораторию данных для различных департаментов нашей компании: логистики, коммерческой дирекции, маркетинга. У них будет возможность проводить исследования, использовать ad hoc-аналитику, ad hoc-репортинг.
Также в будущем предполагается использовать Kubernetes для построения ETL-потоков и тренировки моделей машинного обучения. Kubernetes в реализации VK Cloud подходит для тестирования ML-моделей, так как позволяет использовать нужное количество ресурсов с минимальными затратами. Если обучать за раз десятки тысяч моделей, для этого нужно много ресурсов. Но происходит такое обучение не постоянно, условно — раз в сутки. Держать для постоянного использования необходимые сотни серверов невыгодно. Kubernetes с помощью функции автоскейлинга кластеров позволяет использовать ресурсы для обучения моделей, когда они нужны, а потом возвращать обратно.
Кроме того, в облаке развернут Airflow — оркестратор, позволяющий выстраивать сложные цепочки взаимозависимых процессов, следующих друг за другом, и GitLab для поддержки процессов CI/CD.
Решение реализовано в закрытом контуре внутри облака, установлен криптошлюз + МЭ Check Point для организации VPN, чтобы не было никаких утечек и никто не мог зайти просто так из внешнего интернета.
СУБД Oracle Exadata подразделением Big Data больше не используется, с нее сняли OLAP-нагрузку, она осталась для OLTP.
Облачная платформа для аналитики данных от VK Cloud позволяет быстро масштабироваться и сократить издержки
Облачная Big Data Platform удовлетворяет всем нашим требованиям. Она дает возможность обрабатывать аналитические запросы любой сложности, строить любые прогнозные модели. Кластерные технологии и возможность параллельных вычислений позволяют масштабировать наши ML-решения в любом объеме. Когда мы начнем использовать Kubernetes, это придаст инфраструктуре дополнительную гибкость, мы сможем быстро разворачивать и сворачивать вычислительные ресурсы, снизится стоимость владения.
Мы ожидаем от масштабирования ML-решения для прогнозирования спроса на другие точки сокращения излишних запасов в магазинах на 5% и увеличения продаж на 2%. В рамках всего бизнеса это колоссальный эффект.
Сейчас на единой облачной платформе мы можем использовать ИИ и машинное обучение, тестировать гипотезы с помощью аналитических методов, формировать ad hoc-отчеты. На одной платформе размещены лаборатория данных, разработка и развертывание ML-решений. Различные компоненты поддерживают разные функции и направления в рамках платформы, их можно добавлять и убирать, собирать как аналитический конструктор.
Планы на будущее
Планируем расширять сотрудничество с VK Cloud и развивать Big Data-платформу, дополнить ее новыми компонентами и сервисами, разрабатывать и внедрять ML-алгоритмы в облачной инфраструктуре.
Основные результаты перехода на облачную Data Platform для бизнеса
- Повышение стабильности основных бизнес-процессов, связанное с переходом от СУБД Oracle Exadata по аналитическим задачам и снятием с базы OLAP-нагрузки.
- Гибкое масштабирование инфраструктуры, нужные ресурсы для разработки и развертывания ML-моделей по запросу.
- Возможность построить конвейер для всех уровней работы с данными на одной платформе: можно использовать BI-аналитику, строить ad hoc-отчеты, тренировать ML-модели.
- Удобный и быстрый доступ бизнес-подразделений к данным, которые позволяют принимать взвешенные решения и строить эффективные прогнозы. Так, по нашим ожиданиям, решение для прогнозирования спроса позволит на 2% увеличить выручку и на 5% сократить излишние запасы товаров в магазинах.
Попробуйте наши сервисы
После активации аккаунта мы свяжемся с вами и начислим 3 000 рублей на ваш счет VK Cloud, чтобы вы смогли протестировать сервис в течение 60 дней.
Или оставьте с индивидуальным расчетом
