
-
Русский
-
 English
English

Перенесите обработку данных в облако бесконечной мощности
Облачный сервис для работы с большими данными
Замените дорогую и неэффективную локальную инфраструктуру обработки больших данных, которая нужна всего несколько часов в неделю, на мощную облачную инфраструктуру на основе Hadoop, Spark, ClickHouse.
Предоставляем в двух вариантах











Читайте, как «Ашан» построили конвейер для всех уровней работы с Big Data в публичном облаке VK Cloud
Общий объем данных, загруженных в Big Data Platform на базе VK Cloud, уже сейчас превышает 40 ТБайт, а к концу 2022 года компания прогнозирует его увеличение до 120 ТБайт.
Сейчас на базе платформы в промышленной эксплуатации работает решение для прогнозирования спроса, которое позволило на 2% увеличить выручку от продаж и на 5% сократить излишние запасы товаров в магазинах.
На чем основаны наши решения?
-
 Более 20 лет опыта VK в обработке миллионов пользовательских данных
Более 20 лет опыта VK в обработке миллионов пользовательских данных -
Экспертность в построении собственных платформ для хранения и обработки данных: S3-совместимого хранилища VK Cloud Storage, in-memory платформы Tarantool
-
Расширение экосистемы решений технологиями партнеров-экспертов в области работы с данными


Выберите подходящий вам вариант Cloud Big Data

- Включает сборки для оркестрации с Airflow
- Цена зависит от выбранных CPU, RAM и размера диска
- Без оплаты лицензий

- Доступен Hadoop 3 как сервис
- Цена зависит только от размера диска, количество ядер не влияет на стоимость решения
- Версия Enterprise дает больше функциональности на уровне политик доступа, а также это решение для High Availability с автоматическим поднятием после падения
- Бесплатный тест Enterprise-версии до 3 месяцев
Проконсультируйтесь с архитектором
Планируете строить или развивать облачное решение для работы с Big Data?
Проконсультируйтесь с архитектором: он поможет разобраться в сервисах VK Cloud и даст рекомендации по построению архитектуры эффективного и производительного ИТ-решения.
Консультация бесплатная, оставьте заявку — с вами свяжется менеджер.

Готовые сборки с учетом лучших практик VK
Мы подготовили для вас готовые сборки для решения наиболее частотных задач всего цикла работы с данными.
Если вы опытный пользователь, вы можете задействовать собственную конфигурацию и установить нужные компоненты с помощью веб-интерфейса.
Новые возможности Hadoop 3 в сборках Arenadata
Компоненты, доступные в рамках Cloud Big Data от VK







Примеры и схемы реализации
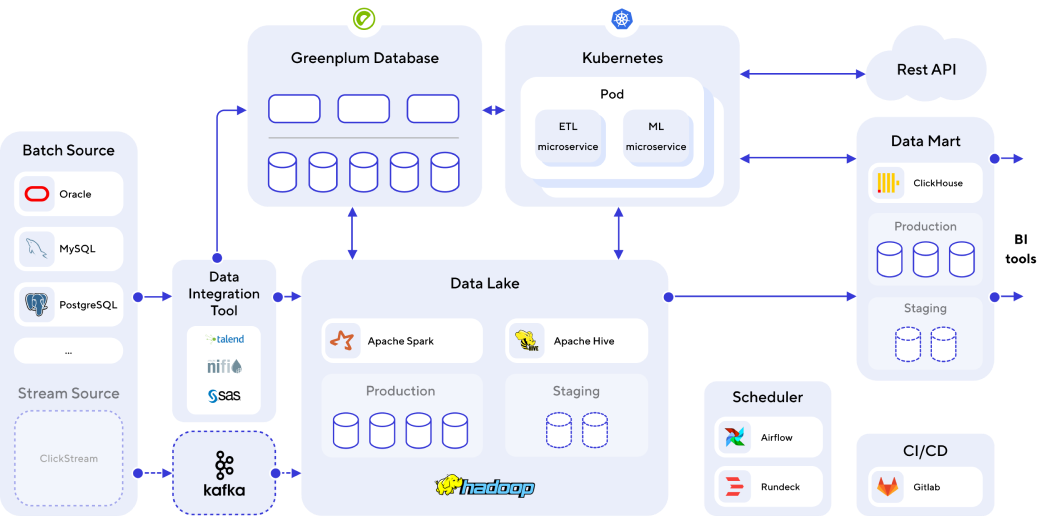
Универсальная аналитическая платформа в облаке. Как «Ашан» построили конвейер для всех уровней работы с Big Data в публичном облаке VK Cloud на основе аналогичной архитектуры, читайте по ссылке.
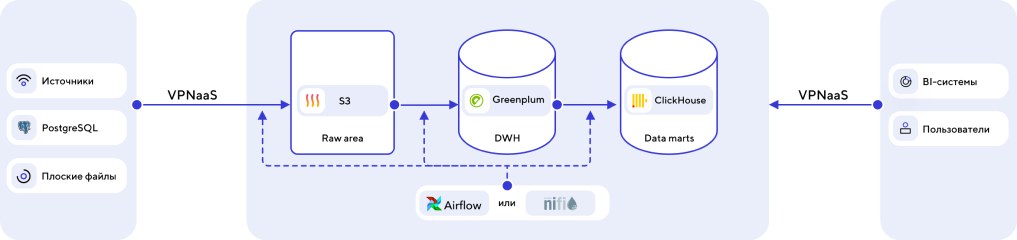
- Оркестрация потоков данных производится с помощью Airflow или NiFi. Оба инструмента можно использовать как сервис в VK Cloud.Основное DWH предлагаем строить на базе ADB/Greenplum. Данная сисема доступна по модели aaS в VK Cloud.
- Витрины данных можно вынести в Clickhouse для ускорения доступа и снижения нагрузки на основную базу DWH, либо оставить внутри Arenadata DB.
- Вместо Arenadata DN для DWH.Также можно использовать Hadoop. Однако мы рекомендуем выбрать ADB, так как в этом случае вы можете описывать все трансформации в рамках ETL процессов, используя SQL.
- Arenadata DB — это enterpise-ready решение, создавшееся под OLAP нагрузки и задачи DWH. В то время как Hadoop обычно больше подходит для решения задач Data Lake. Также используя S3, мы получаем экономически эффективную альтернативу HDFS, где нам не нужно беспокоиться о размере кластера, сайзинге, обслуживании кластера Hadoop.
- Выбрав NiFi, вам будет доступен удобный UI для построения/изменения потоков данных.
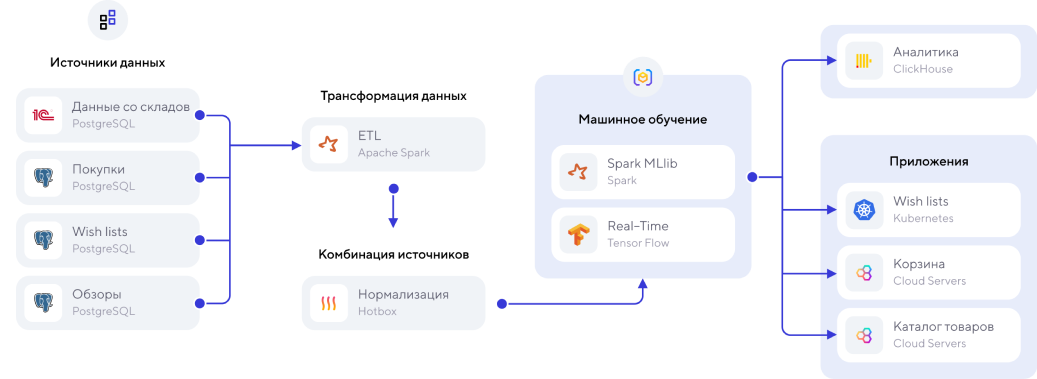
Пример: на основе выбора покупателя предлагать сопутствующие товары «с этим товаром покупают».
Источники данных: клиентское поведение, просмотр товаров, аналитика о прошлых покупках, что покупали с этим товаром.
- Возможность пакетной и потоковой загрузки
- Машинное обучение по поведению покупателей
- Анализ «допродаж»
- Формирование спецпредложений, скидок и акций в зависимости от поведения
- Обработка логов (игровая индустрия)
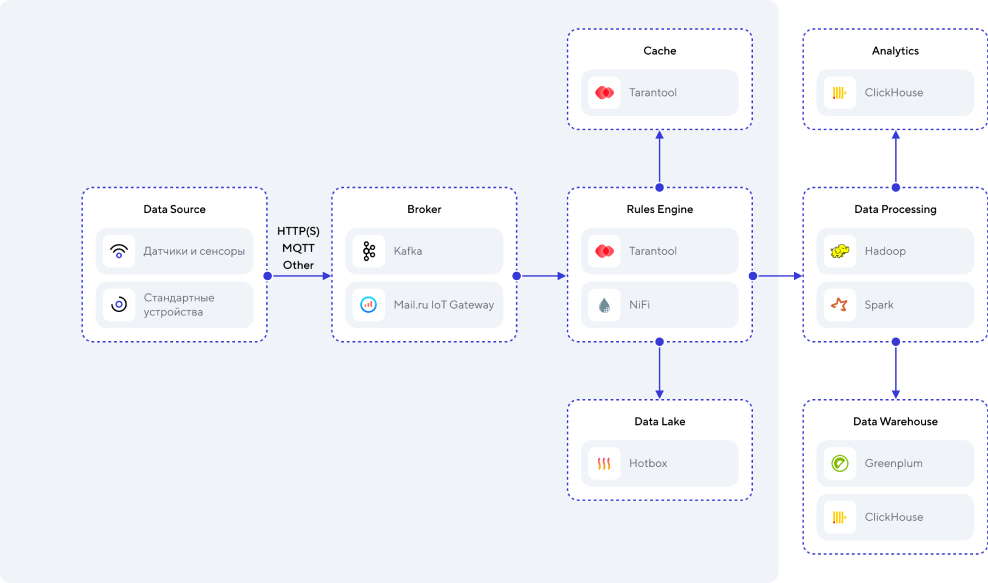
Пример: IoT на производственных линиях, предиктивная аналитика.
Источники данных: станки/роботы на линии передают информацию о своем состоянии оператору.
На основе этой информации можно предупредить поломку оборудования, оптимизировать линию производства, понять загрузку каждого узла сборочной линии. При анализе ретроспективной информации можно увидеть, например, что необходимо выбрать другие сверла/материалы/станки и т. д.
Рассчитайте стоимость
3 000 ₽
на тестирование сервиса
FAQ
В рамках сервиса доступно несколько сборок, которые вы можете использовать на ваш выбор: на базе Hortonworks Data Platform и Hortonworks DataFlow — построено с использованием полностью бесплатных OpenSource-технологий, а также на базе Arenadata Hadoop, дистрибутива Hadoop российской компании-разработчика платформ сбора и обработки данных. Продукт Arenadata максимально приближен к апстрим-версии Hadoop.
Все предоставляемые решения — на базе OpenSource и исключают ситуацию vendor lock-in. Вы всегда сможете перейти на ванильный Apache Hadoop, если этого потребуют ваши задачи.
Сервис Cloud Big Data от VK тарифицируется в зависимости от используемой сборки, но в любом случае вы платите только за используемые ресурсы (и лицензии при использовании Arenadata Hadoop), а также диски в случае остановленных кластеров.
Стоимость использования сборок на базе Hortonworks Data Platform и Hortonworks DataFlow можно посчитать в калькуляторе, она зависит от выбранных CPU, RAM и размера диска. Цена не включает дорогостоящих лицензий сторонних вендоров, так как мы используем полностью OpenSource-сборки Hortonworks до их покупки компанией Cloudera — вы платите только за используемые облачные ресурсы.
В сборках на основе Arenadata Hadoop каждый кластер Big Data тарифицируется только по количеству дискового пространства в кластере, количество ядер не влияет на стоимость решения. Расчет производится при создании кластера: учитывается версия Arenadata Hadoop (на платформе доступны версии Standard, Enterprise и Enterprise Trial) и размер диска. При включении сборки вы начинаете оплачивать лицензию в формате PAYG (по факту потребления ресурсов).
Комплексные проекты на базе VK Data Platform обсуждаются отдельно и рассчитываются в зависимости от используемых сервисов облака и проводимых кастомизаций.
Также возможно вынесение сервиса в сегмент, соответствующий 152-ФЗ. Запросите расчет по использованию сервиса в сегменте 152-ФЗ.
Вы можете протестировать любой из сервисов VK Cloud, который самостоятельно подключается в личном кабинете и не подразумевает оплаты сторонних лицензий, в объеме бонусных 3000 рублей. Бонусы выдаются новым пользователям платформы после полной верификации аккаунта.
Полученные бонусы можно использовать для тестирования сервиса Big Data в сборках Hortonworks. Если вы хотите протестировать сборки на основе Arenadata Hadoop, вы можете запросить доступ к версии Enterprise Trial через форму на этой странице.
Зависит от ваших задач. Некоторые сборки, к примеру, для задач оркестрации это Airflow, доступны на платформе отдельно без выбора провайдера на основе полностью бесплатной OpenSource-версии, оплачиваются только облачные ресурсы. В то время как сборки Hadoop-стека есть в версии от Hortonworks и Arenadata.
Кроме поддерживаемых диструбитивов, сборки отличаются некоторыми другими особенностями. Если вам важен быстрый доступ к Hadoop без оплаты дополнительных лицензий, вы можете выбрать сборку Hortonworks или попробовать Enterprise Trial сборки Arenadata. Если нужно больше функциональности на уровне политик доступа, а также это решение для High Availability с автоматическим поднятием после падения, мы рекомендуем рассмотреть Enterprise-версию Arenadata Hadoop.
Ниже можно ознакомиться с полным списком поддерживаемых компонентов Arenadata Hadoop. Основные отличия версии Enterprise связаны с настройками безопасности и функциональностью для высоких нагрузок, а также возможностью автомасштабирования. Также в Enterprise-версии включено обучение от компании Arenadata.
| Airflow |
| Map Reduce History Server |
| Hbase Master Server |
| Hbase Region Server |
| Hbase Phoenix Query Server |
| Hbase Thrift Server |
| Hive Client |
| Hive Server |
| Hive Metastore |
| Hive Tez, Hive Tez UI |
| HDFS Name Node |
| HDFS Secondary Name Node |
| HDFS Data Node |
| Spark Client |
| Spark History Server |
| Spark Livy |
| Spark Thrift Server |
| MySQL Master Server |
| YARN Node Manager |
| YARN Resource Manager |
| YARN Timeline Server |
| Zookeeper Server |
| Zeppelin Server |
| Apache Flink |
| Solr Server |
| Solr Engine |
| Sqoop Server |
| Knox Server |
| Kerberos config |
HDFS, YARN, MapReduce2, Tez, Hive, HBase, Pig, ZooKeeper, Kafka, Spark2, Zeppelin Notebook, Sqoop, Flume, Ambari, Atlas, Knox, Ranger, Ranger KMS, Spark, Kerberos, Jupyter, Jupyter Hub, Airflow.
Вы можете создать кластер уникальной конфигурации для вашей задачи, подключив нужные компоненты.
Apache Hadoop и Apache Spark — платформы с открытым кодом для надежной и быстрой обработки огромных объемов слабоструктурированных данных из разнородных источников.
Вы можете использовать Hadoop для анализа «озер данных» (Data Lake), индексации веб-сайтов, финансового анализа, научных исследований. Spark оптимален для создания шины микросервисов и анализа в реальном времени, например — сегментации посетителей сайтов, обнаружения мошенничества, мониторинга транспорта.
VK Data Platform — это экосистема масштабируемых облачных сервисов для хранения, обработки и анализа больших данных. Она включает в себя современные инструменты для легкой работы с данными на основе таких платформ как:
- Hadoop, Spark 1/2, Kafka; Airflow, NiFi (в рамках сервиса Cloud Big Data),
- набор Managed-баз данных, в том числе аналитических — ClickHouse и Arenadata DB на основе Greenplum (сервис VK Cloud Databases),
- S3-совместимое объектное хранилище как альтернатива HDFS для надежного хранения (сервис VK Cloud Storage),
- Kubernetes с функцией автомасштабирования для построения аналитических пайплайнов и реализации современного подхода к работе с данными MLOps (сервис VK Cloud Containers),
- высокопроизводительные GPU для любых “тяжелых” задач, в том числе обучения нейросетей (сервис VK Cloud GPU),
- среды разработки для Data Scientists и инженеров данных на базе Jupyter и Zeppelin Notebooks, готовое API компьютерного зрения (сервис VK Cloud ML Platform).
Платформа может быть использована в рамках публичного, частного или гибридного облака. Возможно размещение в сегменте с полным соответствием 152-ФЗ для обработки персональных данных. Платформа может быть использована для применений в области интернета вещей (IoT) и в таком случае включает в себя технологии сбора, обработки и анализа данных в режиме реального времени, управления устройствами и машинным обучением (промышленная платформа интернета вещей IoT Platform от VK).
Не нашли ответ на свой вопрос?
здесь есть ответы на большинство вопросов по настройке сервисов
на портале поддержки, и мы оперативно ответим.

